一年一度的微软「Build开发者大会」前两天刚刚开幕。

微软CEO Satya Nadella在发布会上介绍了这次主要的更新,以ChatGPT为代表的生成式AI成为本次大会的重中之重,其中包括自家的重头戏——Windows Copilot。

演讲视频链接:https://youtu.be/6PRiAexITSs
前段时间刚宣布回归OpenAI的业界大牛、李飞飞高徒、特斯拉前AI总监Andrej Karpathy,也在大会发表了题为「GPT现状」(State of GPT)的主题演讲。

演讲内容主要包括了解ChatGPT等GPT助手的训练途径,他将其分为标记化(Tokenization)、预训练(Pretraining)、监督微调(Supervised Finetuning)和人类反馈强化学习 (RLHF)几步。

另外,他还阐释了有效使用这些模型的实用技术和心智模型的方法,包括提示策略(Prompting Strategies)、微调(Finetuning)、快速增长的工具生态系统及其未来的扩展。
演讲的视频链接小编也放在下面啦,干货满满一起来看看~
视频链接:https://build.microsoft.com/en-US/sessions/db3f4859-cd30-4445-a0cd-553c3304f8e2
GPT助手的训练途径
在进行预训练之前,有2个准备步骤。
首先是数据收集——从不同来源获取大量数据,下图展示的是通过Meta LLaMA模型从Github、维基百科等来源收集的混合数据。

接下来就是标记化,将文本中的单词标记并转换为整数。

然后他用两个模型做了个对比,相比175B参数的GPT-3在300B个代币上训练,而65B参数的LLaMA已经在1-1.4T个代币上训练。
证明了「并不是参数大的模型性能就强」。

预训练阶段
Andrej Karparthy首先介绍了一下预训练中Transformer的工作原理。
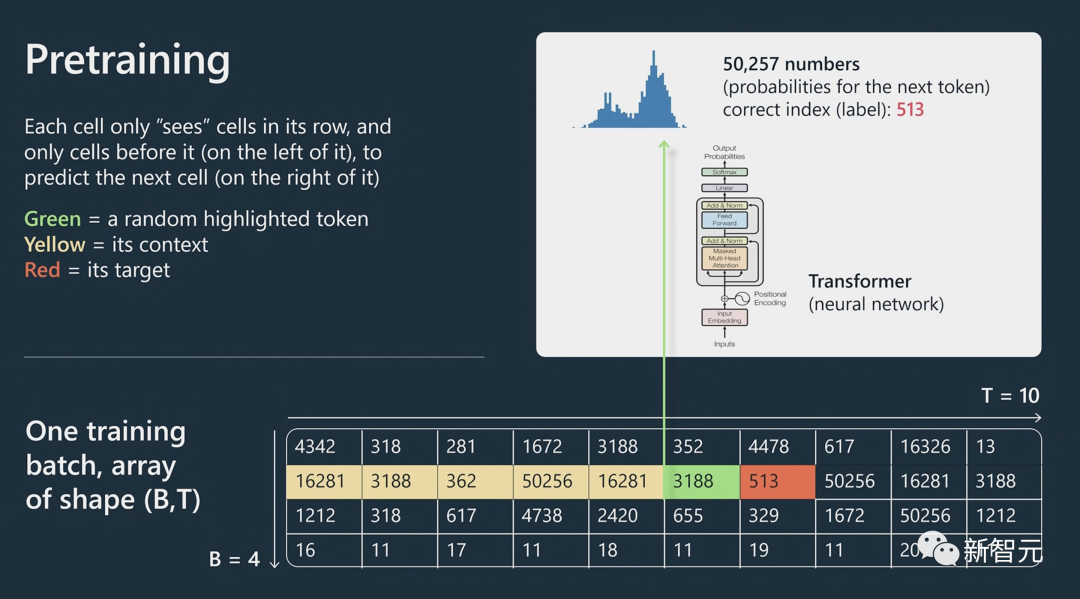
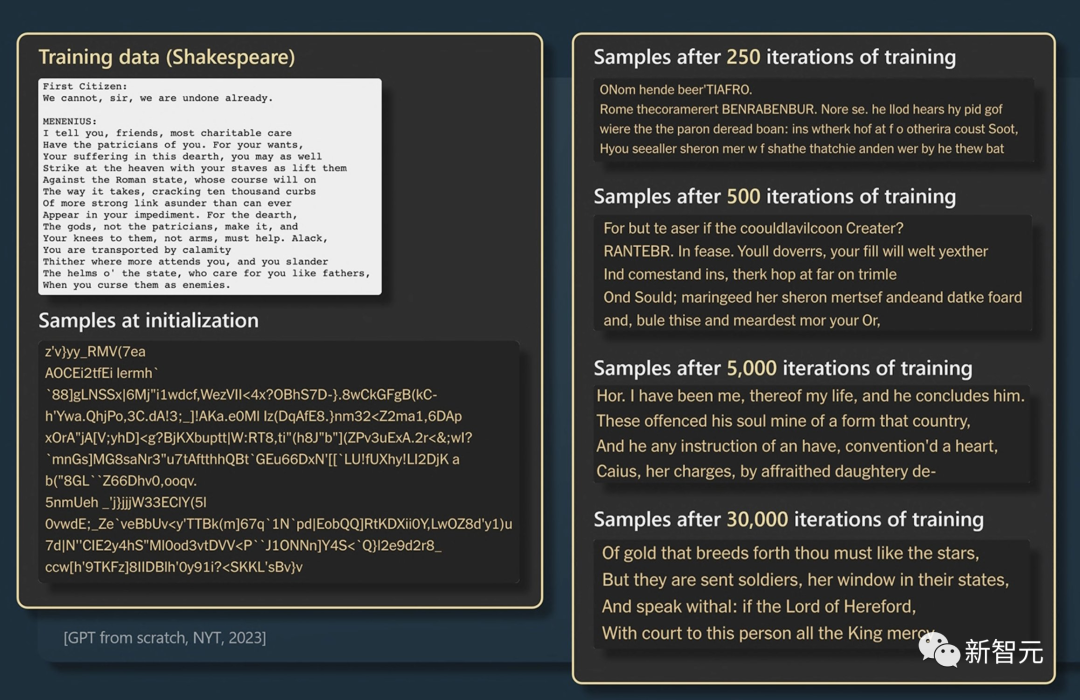
然后向我们展示了GPT模型如何通过不断迭代,更准确地预测莎士比亚诗句中的单词。
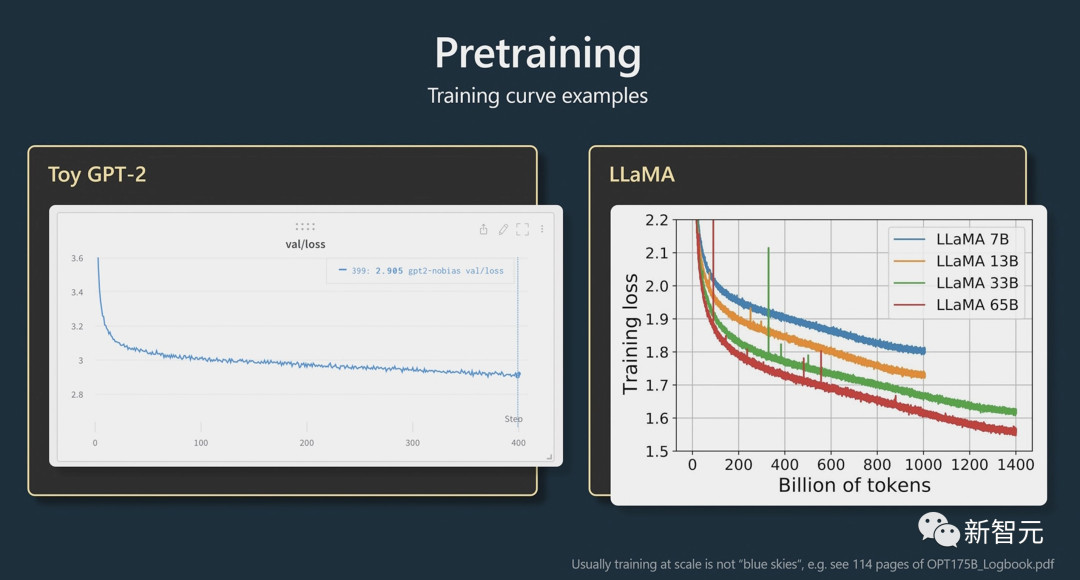
顺便重点强调了一下自家LLaMA模型的牛掰之处,从下图的训练曲线中可以看出LLaMA在训练损失方面明显要比传统GPT-2要低上不少。
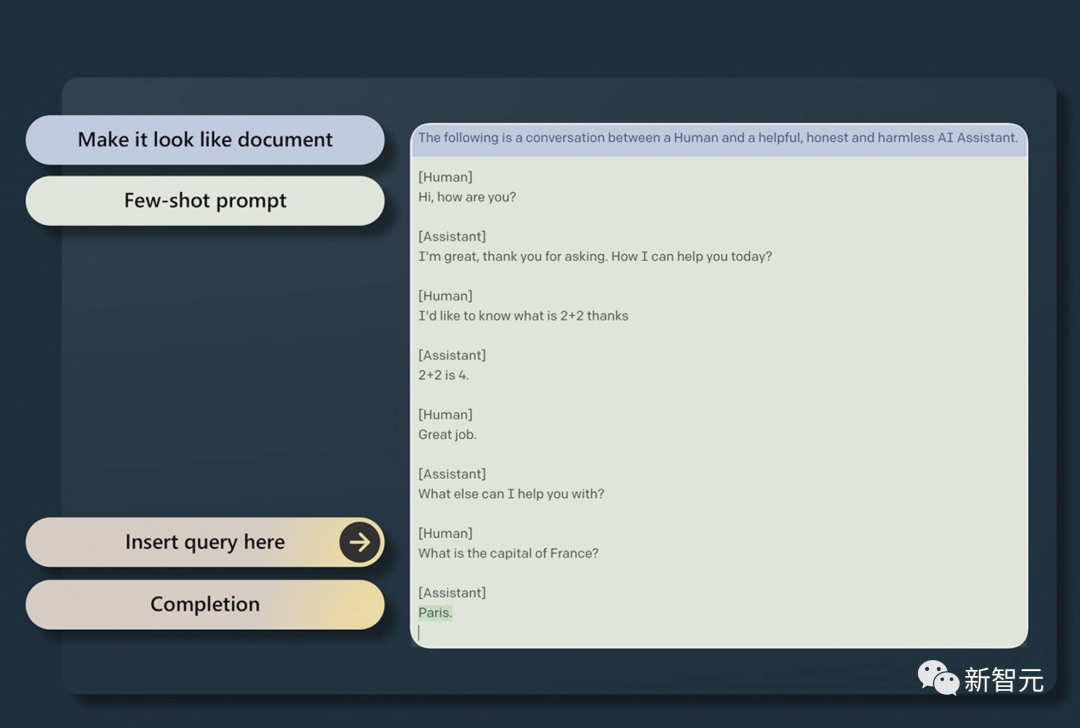
另外围绕GPT-2,许多学者注意到,如果我们以特定方式构建提示,并提供一些示例,那么基础模型将自动完成我们在提示中提供的指令。
基础模型不是助手,他们不会「根据你的提问回答」,他们只会自动完成文本。
比如在下面这篇文本里,对于人类提出的问题,模型通过输入的「Few-shot提示」让它误以为他它自动完成了人工智能和人类之间的聊天。
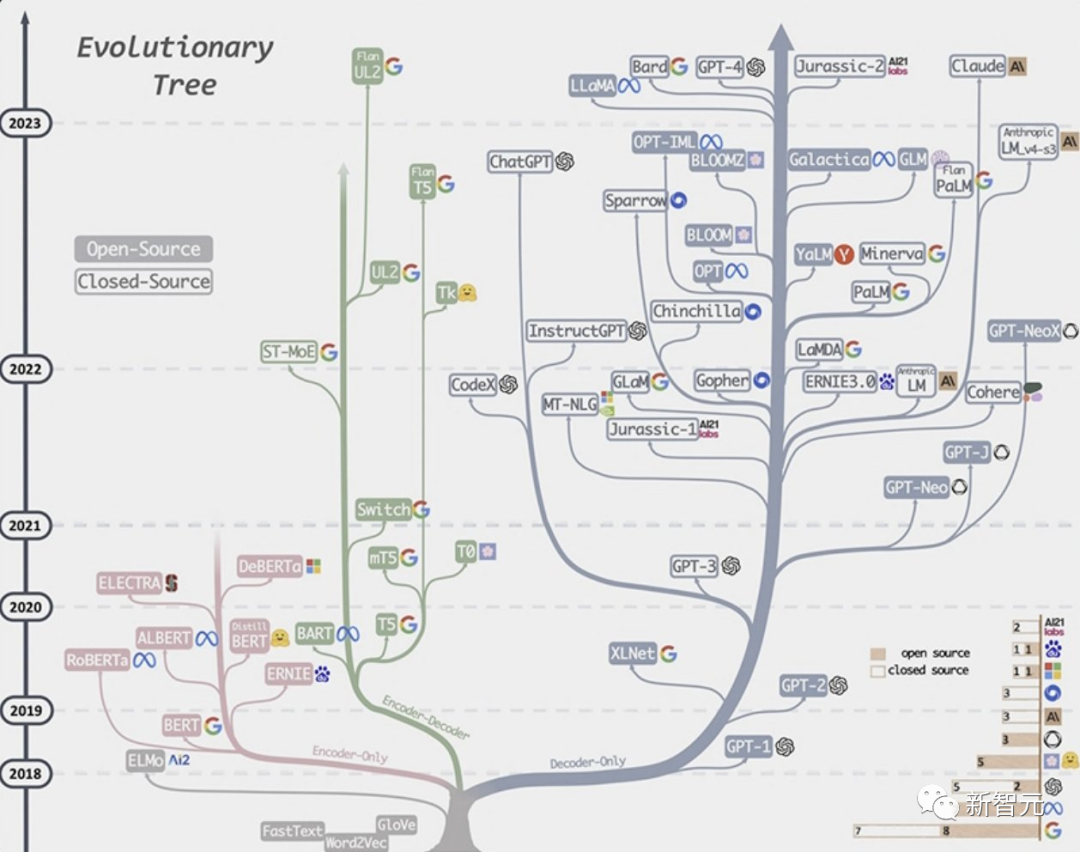
Andrej接下来画出了GPT模型的进化树,可以看到顶端的模型包括谷歌的Bard,Meta的LLaMA。
监督微调
通过使用交换数据集训练模型,我们得到了监督微调后的模型,简称SFT模型。

但SFT模型还不是很好,绝对达不到ChatGPT质量,于是训练继续。
我们使用SFT模型生成问题输出,通过用户对三个版本的比较得出排名最佳的版本,然后根据用户的选择对模型进行重新训练。
而这些决策是根据用户的反馈而得出的,例如当你在ChatGPT中对问题的答案点击或,或选择重新生成响应,这也是RLHF(人类反馈强化学习)的基础。
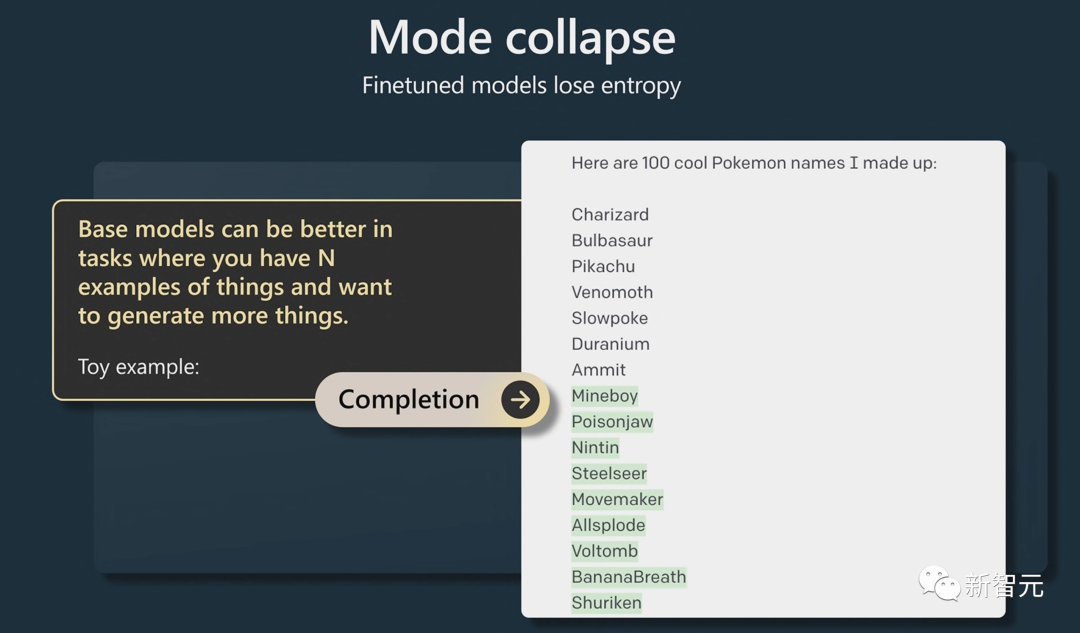
有趣的是,Andrej谈到的RLHF并不是对基本模型的严格改进,因为RLHF模型的熵较小,因此它的创造性可能较少。
基础模型在生成答案的多样性方面可能比微调模型更优秀,例如下图生成的100个宝可梦的名字,基础模型能给你更多想要的答案。
最后,Andrej展示了伯克利大学的校友制作的辅助模型的「野榜」,OpenAI的GPT-4似乎是目前最优秀的。

Andrej接下来展示了人类和GPT模型在处理一个相同的句子的处理过程。
人脑对「加州的人口是阿拉斯加州的53倍」这句话的处理要经历提取信息、事实核查、计算、再次验证等过程。

然而对GPT来说他要做的就是自动完成文本,没有内在的思考对话。
而像Chain of thought「思维链」这样的方法可以为模型提供更多标记或更多思考时间。
这将使模型展示它的工作原理,并给它思考时间以获得更好的答案。

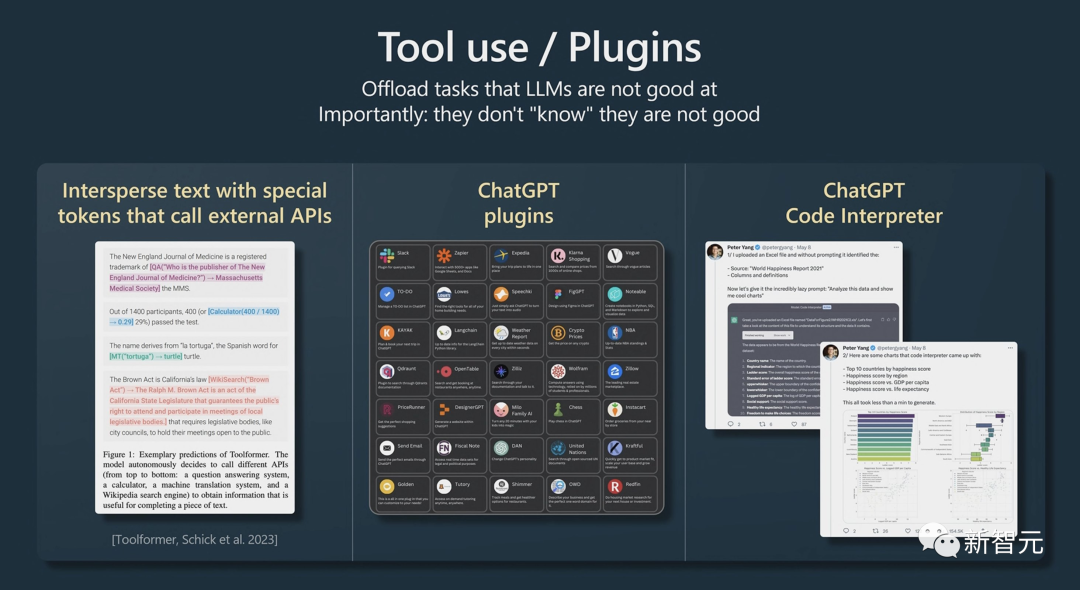
最后还展示了ChatGPT中工具的用法。
演讲最后,Andrej再再再次强调了LLaMA就是迄今最优秀的模型,另外@YannLecun希望他能尽快将其推出商用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。