
译者 | 朱先忠
审校 | 重楼
本篇是关于训练图像分割模型系列文章的第2部分。模型训练的目的是对用户反馈做出响应,并根据反馈(鼠标点击)调整其预测结果。
在第1部分中,我们描述了训练现成的图像分割模型以响应用户反馈的一般策略。在第1部分结束时发现的问题是,手动生成训练模型所需的点击是乏味、耗时的,并且如果数据集非常大和/或模型需要经常重新训练,这种方式可能根本不可行。因此,生成点击需要自动化——这就是本篇的主题。
问题
首先,让我们再来回顾一下我们正在试图解决的问题:

图像来源:乳腺超声图像数据集
左侧矩形显示的是带有正确标注标签的图像;感兴趣区域(RoI:region of interest)由人类专家用黄色标记;这是我们期望从模型中得到的预测的理想形状。中间矩形内容是来自模型的实际预测。右侧的矩形显示了真阳性区域(标签和预测一致)、假阳性区域(模型预测RoI,但标签中没有这样的东西)和假阴性区域(模型什么都不预测,但有实际的RoI)。TP区域以白色显示,FP区域以绿色显示,FN区域以红色显示。
为了引导模型的预测,我们在TP和FN区域分别放置了正(绿色)点击,在FP区域放置了负(红色)点击,然后用图像中包含的点击训练新模型。
对于操作人员来说,放置点击是直观的。但是,如果你想将流程分解为单独的逻辑步骤和标准的话,则会变得非常复杂:
- 将TP、FP、FN区域拆分为单独的连续段
- 将非常小的片段视为不相关而丢弃
- 对于剩余的每个片段,根据片段区域决定将被放置在其中的点击总数
- 点击不能放得太近
- 点击不能放得离线段边缘太近
最后两个标准很难做到。其中的模糊性(“不太接近”)以及这两个标准相互矛盾的事实,使得很难以保证收敛到模仿操作员操作的解决方案的方式来生成点击。
值得欣喜的是,下面我们将展示另外一种方法,它将数学概念(Voronoi镶嵌)与物理学知识(能量和模拟退火)相结合,能够顺利产生我们所需的结果。
Voronoi镶嵌(Tesselation)
维基百科页面中很好地解释了Voronoi镶嵌这个概念;但是,在这里我想再补充解释一下这一概念。

在左边的矩形中,我们有一个正方形区域,其中有几个种子点。对于任何种子点,帧(图像片断)中必须有一个区域,其中所有像素都更靠近该种子,而不是所有其他种子。在右边的矩形中,我们展示了这些图像片断,颜色编码与种子相匹配。每个图像片断被称为Voronoi单元,找到图像片断的过程的结果被称为沃罗诺伊镶嵌。
本例中的种子是随机选择的。我们得到的镶嵌结果是不一致的。为了获得均匀的镶嵌,种子还必须是其对应图像片断的质心(或接近质心)——这被称为质心Voronoi镶嵌。在众多可能的例子中,下面是一个非常琐碎的例子:

要找到将导致区域的质心Voronoi镶嵌或近似的点击坐标(种子),可以使用类似Lloyd算法的方法,而且速度非常快。这里有一个Lloyd算法的模拟器,它可以在你的浏览器中实时工作。但存在两个问题:
- Lloyd算法通常用于平铺矩形形状。目前尚不清楚它将如何(或是否)推广到我们需要为模型平铺的任意形状。
- 只有当形状是凸的时,我们才需要质心平铺。当形状是凹形时,质心可能会落在我们平铺的区域之外,这根本不是我们想要的(点击会在区域之外)。
因此,我们需要一种能够处理任意形状的东西,即使形状是凹形的,也能将点击保持在区域内,并且在琐碎的矩形情况下表现得像Lloyd算法。质心Voronoi平铺的推广,适用于任意形状,即使是凹形。这是下一节的主题。
能量模拟退火
考虑这种下图中的平铺:

单击分布足够均匀,并且单击坐标离质心不远(所有形状都是凸的)。就我们的目的而言,这是一个不错的分布。我们能找到一个与点击坐标相对应的目标函数吗?我们可以反复尝试最大化或最小化该函数,从而得出这样的分布吗?
让我们看看点击周围的空间:
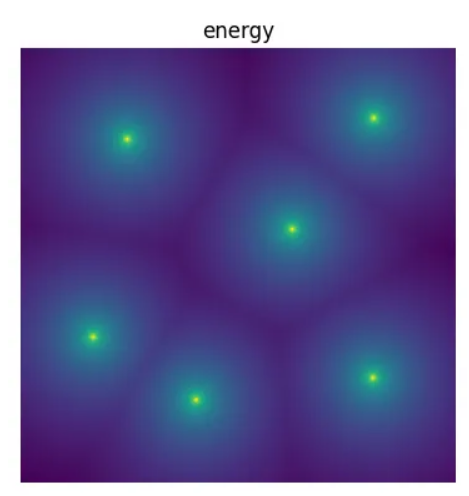
像素能量热图
想象一下,图像中的每个像素都被分配了一个“能量”。只有一次单击——最近的单击,会贡献像素的能量。所有其他点击都没有任何作用。任何像素的能量与其最近点击的距离成反比。因此,要找到任何像素的能量,我们需要:
- 找到最近的点击
- 计算像素到点击的距离
- 计算距离的倒数,即像素的能量
上面显示的图像只是像素能量的热图,给出了点击分布。Voronoi瓷砖(Voronoi Tiles)的边缘已经被相邻点击之间最暗的区域所暗示。
如果我们计算所有像素的总能量,然后四处移动点击,寻找总能量最高的点击位置,这会导致区域的均匀平铺吗?事实上,这正是上面显示的点击分布获得的方式:
- 从完全随机的点击坐标开始
- 计算感兴趣区域中所有像素的总能量
- 对点击坐标应用模拟退火算法,以找到最大化总能量的坐标
完整的代码显示在链接地址https://github.com/FlorinAndrei/segmentation_click_train/blob/main/uniform_clicks.py处。该算法很稳健,可以很好地处理凹形形状——这里是一个在镰刀形片段中以视觉上均匀的方式放置点击的例子:

将点击放置在凹形区域
分割片段是较浅的蓝色阴影,镰刀的形状,与深色背景形成对比。其中,点击对应于最亮的地方。
点击不会太靠近片段的边缘,因为这会减少总能量(片段边缘以外的像素没有能量)。它们不会靠得太近,因为这不会“激发”远离紧密点击组的像素。该算法是自我调节的。
注意:这个问题与手机信号塔覆盖问题有相似之处,即你试图在地图上放置N个手机信号塔,以便在大多数地区信号尽可能强。
再回到分割模型
概括一下,我们正在尝试训练图像分割模型,使其对用户反馈(鼠标点击)做出响应。整个过程是:
- 将图像数据集拆分为5个组
- 为每个折叠训练分割模型;这就产生了一组5个基线模型
- 使用基线模型对所有图像进行预测;每个模型都对训练中没有看到的图像进行预测
- 将预测与标签进行比较;提取包含真阳性、假阳性、假阴性预测的所有区域
- 将所述TP、FP、FN区域分割成连续的段;丢弃最小的分段(小于100个像素左右)
- 对于每个片段,生成统一的点击,如本文所示;点击次数取决于片段的面积:较大的片段会收到更多的点击,达到合理的限制(对于512×512像素的图像,4…5左右)
- 将所有图像信息移动到B频道,腾出R和G频道,将点击嵌入R和G通道;TP和FN区域的点击在G通道中(正点击);FP区域的点击在R通道中(负点击)
- 使用点击增强图像,在相同的褶皱上训练一组新的5个模型;这些是经过点击训练的模型,是整个项目的最终产物
以下是根据实际基线模型预测为图像片段生成的均匀点击的一些示例。我们从数据集中挑选了3张图像,用基线模型进行了预测,并查看了每张图像的TP、FP和FN片段。每个片段都是比背景浅的蓝色阴影,点击对应于每个片段中最亮的点。

图像来源:乳腺超声图像数据集
点击最终或多或少地被放置在操作员将要放置的位置:彼此不要太近,也不要太靠近边缘,有利于每个片段中的大块或宽区域。点击分布在视觉上看起来是均匀的。
总结
至此,我们已经成功训练了现成的图像分割模型来响应用户反馈,而不会以任何方式改变它们的架构,也不会在ImageNet上从头开始重新训练它们。
需要说明的是,经过点击训练的模型并不一定比基线模型表现得更好。如图所示,通过点击进行训练只能使模型对用户反馈做出响应。当然,在用于创建5个训练组的数据集上,点击训练的模型将大大优于基线模型。这是因为创建点击本质上是在训练和测试之间泄露数据。在以前100%看不见的数据上,点击训练模型和基线模型的性能相同。
以下是点击训练模型对用户反馈的响应方式的更多应用情形。
- 给定视频中显示两幅不同的图像。在这两张图中,你可以看到模型对其预测的RoI有很高的信任度。在预测的RoI中放置负面点击的尝试不是很成功——该模型继续将该区域预测为RoI。
- 该模型确实接受了将其他领域作为潜在ROI的建议。
在上述两种情况下,您都可以从模型中看到两种输出:纯分割和热图。热图只是RoI的可能性图。
链接、引文、评论
本文中的这个项目是我在数据科学硕士研究的最后一个学期的毕业项目的延伸。
毕业项目和这项工作都是在威斯康星大学拉克罗斯分校的乳腺超声图像计算机辅助诊断(CADBUSI)项目中完成的,由Jeff Baggett博士监督。参考地址:https://datascienceuwl.github.io/CADBUSI/。
包含本文代码的GitHub存储库:https://github.com/FlorinAndrei/segmentation_click_train。
本文中使用的所有超声图像都是乳腺超声图像数据集的一部分,可在CC BY 4.0许可证下获得。引文链接有:
Al-Dhabyani, W., Gomaa, M., Khaled, H., & Fahmy, A. (2019)。《乳腺超声图像数据集》(Dataset of Breast Ultrasound Images)。ResearchGate。检索日期:2023年5月1日,论文:https://www.sciencedirect.com/science/article/pii/S2352340919312181。
其他链接、引用和评论:
- Liu, Q., Zheng, M., Planche, B., Karanam, S., Chen, T., Niethammer, M., & Wu, Z. (2022)。《伪点击:具有点击模仿的交互式图像分割》(PseudoClick: Interactive Image Segmentation with Click Imitation)。arXiv.org。检索日期:2023年5月1日,论文:https://arxiv.org/abs/2207.05282。
- Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J. M., & Luo. P. (2021)。《SegFormer:一种简单高效的变压器语义分割设计》(SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers)。arXiv.org。检索日期:2023年5月1日,论文:https://arxiv.org/abs/2105.15203。
- 《HuggingFace的预训练SegFormer模型》(Pretrained SegFormer models at HuggingFace):https://huggingface.co/docs/transformers/model_doc/segformer。
最后,本文中不属于乳腺超声图像数据集的图像由作者创建。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Train Image Segmentation Models to Accept User Feedback via Voronoi Tiling, Part 2,作者:Florin Andrei
© 版权声明
文章版权归作者所有,未经允许请勿转载。


