
神经辐射场(NeRF)已经成为一种流行的新视图合成方法。虽然 NeRF 正在快速泛化到更广泛的应用以及数据集中,但直接编辑 NeRF 的建模场景仍然是一个巨大的挑战。一个重要的任务是从 3D 场景中删除不需要的对象,并与其周围场景保持一致性,这个任务称为 3D 图像修复。在 3D 中,解决方案必须在多个视图中保持一致,并且在几何上具有有效性。
本文来自三星、多伦多大学等机构的研究人员提出了一种新的三维修复方法来解决这些挑战,在单个输入图像中给定一小组姿态图像和稀疏注释,提出的模型框架首先快速获得目标对象的三维分割掩码并使用该掩码,然后引入一种基于感知优化的方法,该方法利用学习到的二维图像再进行修复,将他们的信息提取到三维空间,同时确保视图的一致性。
该研究还通过训练一个很有挑战性的现实场景的数据集,给评估三维场景内修复方法带来了新的基准测试。特别是,该数据集包含了有或没有目标对象的同一场景的视图,从而使三维空间内修复任务能够进行更有原则的基准测试。

- 论文地址:https://arxiv.org/pdf/2211.12254.pdf
- 论文主页:https://spinnerf3d.github.io/
下面为效果展示,在移除一些对象后,还能与其周围场景保持一致性:

本文方法和其他方法的比较,其他方法存在明显的伪影,而本文的方法不是很明显:

方法介绍
作者通过一种集成的方法来应对三维场景编辑任务中的各种挑战,该方法获取场景的多视图图像,以用户输入提取到的 3D 掩码,并用 NeRF 训练来拟合到掩码图像中,这样目标对象就被合理的三维外观和几何形状取代。现有的交互式二维分割方法没有考虑三维方面的问题,而且目前基于 NeRF 的方法不能使用稀疏注释得到好的结果,也没有达到足够的精度。虽然目前一些基于 NeRF 的算法允许去除物体,但它们并不试图提供新生成的空间部分。据目前的研究进展,这个工作是第一个在单一框架中同时处理交互式多视图分割和完整的三维图像修复的方法。
研究者利用现成的、无 3D 的模型进行分割和图像修复,并以视图一致性的方式将其输出转移到 3D 空间。建立在 2D 交互式分割工作的基础上,作者所提出的模型从一个目标对象上的少量用户用鼠标标定的图像点开始。由此,他们的算法用一个基于视频的模型初始化掩码,并通过拟合一个语义掩码的 NeRF ,将其训练成一个连贯的 3D 分割。然后,再应用预先训练的二维图像修复到多视图图像集上,NeRF 拟合过程用于重建三维图像场景,利用感知损失去约束 2 维画图像的不一致,以及画深度图像规范化掩码的几何区域。总的来说,研究者们提供了一个完整的方法,从对象选择到嵌入的场景的新视图合成,在一个统一的框架中对用户的负担最小,如下图所示。

综上所述,这篇工作的贡献如下:
- 一个完整的 3D 场景操作过程,从用户交互的对象选择开始,到 3D 修复的 NeRF 场景结束;
- 将二维的分割模型扩展到多视图情况,能够从稀疏注释中恢复出具有三维一致的掩码;
- 确保视图一致性和感知合理性,一种新的基于优化的三维修复公式,利用二维图像修复;
- 一个新的用于三维编辑任务评估的数据集,包括相应的操作后的 Groud Truth。
具体到方法上面,该研究首先描述了如何从单视图注释中初始化一个粗略的 3D 掩码。将已标注的源代码视图表示为 I_1。将对象和源视图的稀疏信息给一个交互式分割模型,用来估计初始源对象掩码 。然后将训练视图作为一个视频序列,与
。然后将训练视图作为一个视频序列,与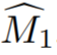 一起给出一个视频实例分割模型 V ,以计算
一起给出一个视频实例分割模型 V ,以计算 ,其中
,其中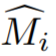 是 I_i 的对象掩码的初始猜测。初始的掩码通常在边界附近是不准确的,因为训练视图实际上并不是相邻的视频帧,而视频分割模型通常是未知 3D 的。
是 I_i 的对象掩码的初始猜测。初始的掩码通常在边界附近是不准确的,因为训练视图实际上并不是相邻的视频帧,而视频分割模型通常是未知 3D 的。

多视图分割模块获取输入的 RGB 图像、相应的相机内在和外部参数,以及初始掩码去训练一个语义 NeRF 。上图描述了语义 NeRF 中使用的网络;对于点 x 和视图目录 d,除了密度 σ 和颜色 c 外,它还返回一个 pre-sigmoid 型的对象 logit,s (x)。为了其快速收敛,研究者使用 instant-NGP 作为他们的 NeRF 架构。与光线 r 相关联的期望客观性是通过在等式中呈现 r 上的点的对数而不是它们相对于密度的颜色而得到的:

然后使用分类损失进行监督:

用于监督基于 NeRF 的多视图分割模型的总体损失为:

最后,采用两个阶段进行优化,进一步改进掩码;在获得初始三维掩码后,从训练视图呈现掩码,并用于监督二次多视图分割模型作为初始假设(而不是视频分割输出)。

上图显示了视图一致的修复方法概述。由于数据的缺乏妨碍了直接训练三维修改修复模型,该研究利用现有的二维修复模型来获得深度和外观先验,然后监督 NeRF 对完整场景的渲染拟合。这个嵌入的 NeRF 使用以下损失进行训练:

该研究提出具有视图一致性的修复方法,输入为 RGB。首先,该研究将图像和掩码对传输给图像修复器以获得 RGB 图像。由于每个视图都是独立修复的,因此直接使用修复完的视图监督 NeRF 的重建。本文中,研究者并没有使用均方误差(MSE)作为 loss 生成掩码,而是建议使用感知损失 LPIPS 来优化图像的掩码部分,同时仍然使用 MSE 来优化未掩码部分。该损失的计算方法如下:

即使有感知损失,修复视图之间的差异也会错误地引导模型收敛到低质量几何(例如,摄像机附近可能形成 “模糊” 几何测量,以解释每个视图的不同信息)。因此,研究员使用已生成的深度图作为 NeRF 模型的额外指导,并在计算感知损失时分离权值,使用感知损失只拟合场景的颜色。为此,研究者使用了一个对包含不需要的对象的图像进行了优化的 NeRF,并渲染了与训练视图对应的深度图。其计算方法是用到相机的距离而不是点的颜色代替的方法:

然后将渲染的深度输入到修复器模型,以获得修复完的深度图。研究发现,使用 LaMa 进行深度绘制,如 RGB,可以得到足够高质量的结果。这个 NeRF 可以是与用于多视图分割的相同模型,若使用其他来源来获取掩码,如人工注释的掩码,一个新的 NeRF 将被安装到场景中。然后,这些深度图被用来监督已修复的 NeRF 的几何形状,通过其渲染深度然后将渲染的深度输入到修复器模型,以获得修复完的深度图。研究发现,使用 LaMa 进行深度绘制,如 RGB,可以得到足够高质量的结果。这个 NeRF 可以是与用于多视图分割的相同模型,若使用其他来源来获取掩码,如人工注释的掩码,一个新的 NeRF 将被安装到场景中。然后,这些深度图被用来监督已修复的 NeRF 的几何形状,通过其渲染深度到修复的深度的![]() 到修复的深度的距离:
到修复的深度的距离:

实验结果
多视图分割:首先评估 MVSeg 模型,没有任何编辑修复。在本实验中,假设稀疏图像点已经给出了一个现成的交互式分割模型,并且源掩码是可用的。因此,该任务是将源掩码传输到其他视图中。下表显示,新模型优于 2D(3D 不一致)和 3D 基线。此外研究者提出的两阶段优化有助于进一步改进所得到的掩码。

定性分析来说,下图将研究人员的分割模型的结果与 NVOS 和一些视频分割方法的输出进行了比较。与 3D 视频分割模型的粗边相比,他们的模型降低了噪声并提高了视图的一致性。虽然 NVOS 使用涂鸦(scribbles)不是研究者新模型中使用的稀疏点,但新模型的 MVSeg 在视觉上优于 NVOS。由于 NVOS 代码库不可用,研究人员复制了已发布的 NVOS 的定性结果(更多的例子请参见补充文档)。

下表显示了 MV 方法与基线的比较,总的来说,新提出的方法明显优于其他二维和三维修复方法。下表进一步显示,去除几何图形结构的引导会降低已修复的场景质量。

定性结果如图 6、图 7 所示。图 6 表明,本文方法可以重建具有详细纹理的视图一致场景,包括有光泽和无光泽表面的连贯视图。图 7 表明, 本文的感知方法减少了掩码区域的精确重建约束,从而在使用所有图像时防止了模糊的出现,同时也避免了单视图监督造成的伪影。


© 版权声明
文章版权归作者所有,未经允许请勿转载。


