
过去几个月里,Meta的LLaMA引领了一场语言模型的开源狂潮,并且随着大众对语言模型训练研究的深入,很多问题也都有了答案。
比如需要人类反馈和强化学习来对齐语言模型吗?语言模型在ChatGPT模拟数据上的效果怎么样?是否可以用多个epoch训练语言模型?
最近,lighting.ai的首席教研员、前威斯康星大学麦迪逊分校统计学助理教授Sebastian发布了一篇博客,介绍了一些解决上述疑问的研究成果。

在特定任务上微调语言模型
Goat模型是一个基于7B LLaMA微调的模型,在算术任务上的性能优于GPT-4,在零样本设置中还超越了75倍参数量的540B PaLM

论文链接:https://arxiv.org/pdf/2305.14201.pdf
Goat相当于是一个专有用途的微调LLM,从直觉来看也肯定会优于GPT-4等通用聊天机器人。

不过对业务来说,这篇论文也打开了专用模型的大门,毕竟大部分公司追求的都是在某一领域超越GPT-4即可。
虽然Goat并不是第一个针对特定任务进行微调的语言模型,还有大量的基于FLAN微调的工作,但Goat取得成功的两个要素在于:
1. 在一个更好的基础语言模型上,在目标任务(相对于通用预训练或指令微调)上进行有监督微调;
2. LLaMA对数字的分词技术(将每个数字单独分配一个token)
从实验结果可知二者的结合是很重要的,第一点是因为原始7 B LLaMA基础型号不如GPT-4;第二点是因为对OPT,GPT-J等模型的微调结果不如Goat好,因为其他模型的数字分词技术不统一。
也有人有疑问,为什么不用Wolfram Alpha或常规计算器等工具进行算数计算,而非要用语言模型算数?
对这篇论文来说,算术任务可以很容易地合成数据集,评估也更方便,方便测试微调性能。
从Goat到Gorilla
另一个微调LLM以提高某一特定功能的例子是Gorilla,一个专门用于生成API调用的LLM。

论文链接:https://arxiv.org/abs/2305.15334
研究人员使用LLaMA-7 B基础模型,并对来自Torch Hub、TensorFlow Hub和HuggingFace的1645个API调用进行了微调,发现经过微调的Gorilla在API调用上优于其他未进行微调的LLM。

让微调更高效
之前提到的Goat模型使用低秩自适应(LoRA)技术以提高微调的效率,可以在单个24GB显存GPU上对70亿参数LLaMA模型进行微调。

论文链接:https://arxiv.org/abs/2305.14314
而最近发布的一个新技术QLoRA(量化LoRA)可以在单个 48GB显存的GPU上训练650亿参数的LLaMA模型,量化的4位参数设置下,训练后得到的65B Guanaco模型保持了完整的16位微调任务性能,并且仅在微调24小时后就达到了ChatGPT性能的99.3%。

微调语言模型需要多少数据?
对于想要定制语言模型的从业者和研究人员来说,起步难题就是获得足够的数据进行微调。
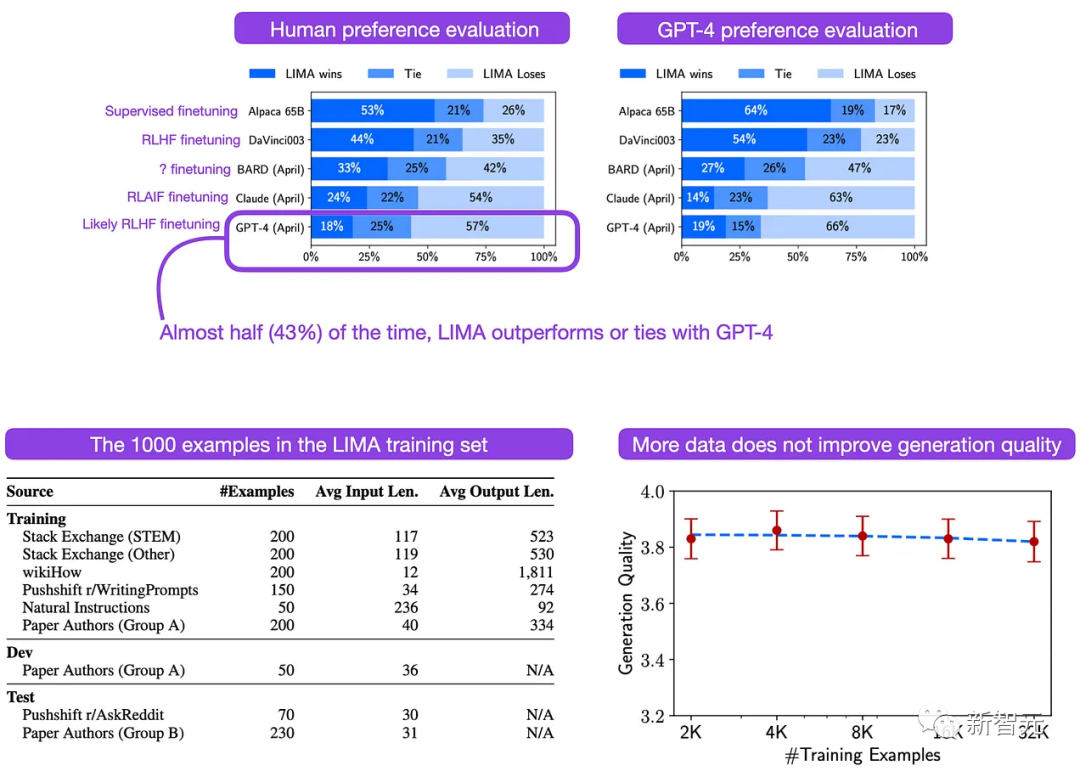
最近发布的LIMA论文可能是一次微调上的突破,研究结果表明,仅在1000个示例上进行微调的65 B LLaMA模型(以有监督的方式)并不落后于ChatGPT / GPT3.5等更大的模型。

论文链接:https://arxiv.org/abs/2305.11206
研究人员发现,在57%的情况下,GPT-4仍然更好,但他们观察到,在43%的情况下,LIMA优于或相当于GPT-4,已经非常强了;或者从另一个角度来看,大约有一半的情况,LIMA可以优于GPT-4的前身ChatGPT/GPT3.5(也叫DaVinci 003)。

不过还有一个问题是,同样是有监督微调后的LLaMA模型,为什么LIMA的表现比Alpaca好这么多?
首先,LIMA基于65B LLaMA模型,而原始Alpaca模型基于7B LLaMA基础模型。
为了公平对比,作者使用65B基础模型复刻了Alpaca的训练过程,即使用原始Alpaca项目中描述的52000个样本进行训练。
所以可以得出结论,差异实际上来源于作者为LIMA精心策划的训练集的质量,使得LIMA可以击败在52倍数据上训练的相同的65B LLaMA基础模型。
不过还缺少的一个基线对比和消融研究是LIMA与使用RLHF而非有监督学习进行微调的65B LLaMA基础模型。
虽然LIMA的实验结果非常有前景,不过有一篇论文的研究结果也需要注意,模仿学习得到的语言模型可能并没有想象中的那么强。

论文链接:https://arxiv.org/abs/2305.15717
最近几个月,根据来自其他语言模型(如ChatGPT)的数据对LLM进行微调已成为常见做法,不过研究人员发现,众包工作者对这些所谓的模仿模型评价很高。但事实证明,这些模仿模型只倾向于模仿上游语言模型的风格,而非真实性。

LIMA论文虽然没有使用模仿数据,而是使用精心设计的数据集,但仍然值得强调的是,评估结果有时似乎好得令人难以置信,我们需要更好的基准测试。
人类反馈强化学习的替代方案
最近几个月,有监督微调成了微调语言模型的新范式,比如LIMA论文也是使用有监督微调,但也存在其他方法来替代基于人类反馈的强化学习。
直接偏好优化(DPO,Direct Preference Optimization)也是一种全新的、可替代强化学习的方法,使用接近策略优化(PPO)的人类反馈,用于ChatGPT等指令微调模型。
研究人员表明,在RLHF中拟合奖励模型的交叉熵损失可以直接用于微调语言模型,而且根据基准测试,使用DPO更有效,并且在回复质量方面通常也优于RLHF/PPO

多个epoch训练会怎么样?
微调模型需要一个预训练的基础模型,所以一个很自然的需求就是获得更好的基础模型。
对经典的机器学习模型、深度神经网络以及最新的视觉Transformer模型训练数百个epoch是很常见的操作,不过大型语言模型通常指训练1个epoch,如果训练超过一个epoch会发生什么?

论文链接:https://arxiv.org/pdf/2305.13230.pdf
事实证明,互联网上的高质量文本数据比想象中的更少,此外,如果受版权保护的材料在未来被要求删除,可能会进一步缩小数据集的规模。
论文实验结果表明,要是因为数据量少就训练多个epoch,可能会导致模型过拟合。

另一个有趣的结论是:dropout可以帮助减少过度拟合,但其他技术如权重衰减却并不能。
不过现在常用的大型语言模型模型,如LLaMA,Gopher,Chinchilla,GPT-3和PaLM都没有使用dropout,因为会减慢学习速度。
三个开放问题
1. 只重复训练像LIMA这样的高质量数据怎么样?
从直觉上来看,这是有意义的,可能会对模型质量提升有所帮助,不过坏消息是,从实际来看没有多大帮助。
研究人员对维基百科的数据进行了一项相关实验,相比C4来说他们认为维基百科是高质量的,不过事实证明,当维基百科数据在训练期间重复多个epoch后也发生了类似的退化现象。
2. 数据增强有用吗?
目前有几种数据增强技术,包括回译、同义词替换、句子重排以及使用模型合成数据(例如GPT-4),但还没有数据增强对模型训练效果的全面分析。
3. 微调是什么样的?同样的规则适用吗?
根据作者的经验,训练3-5个小epoch是值得的,但目前也没有相关研究全面分析。
更高效的视觉Transformer
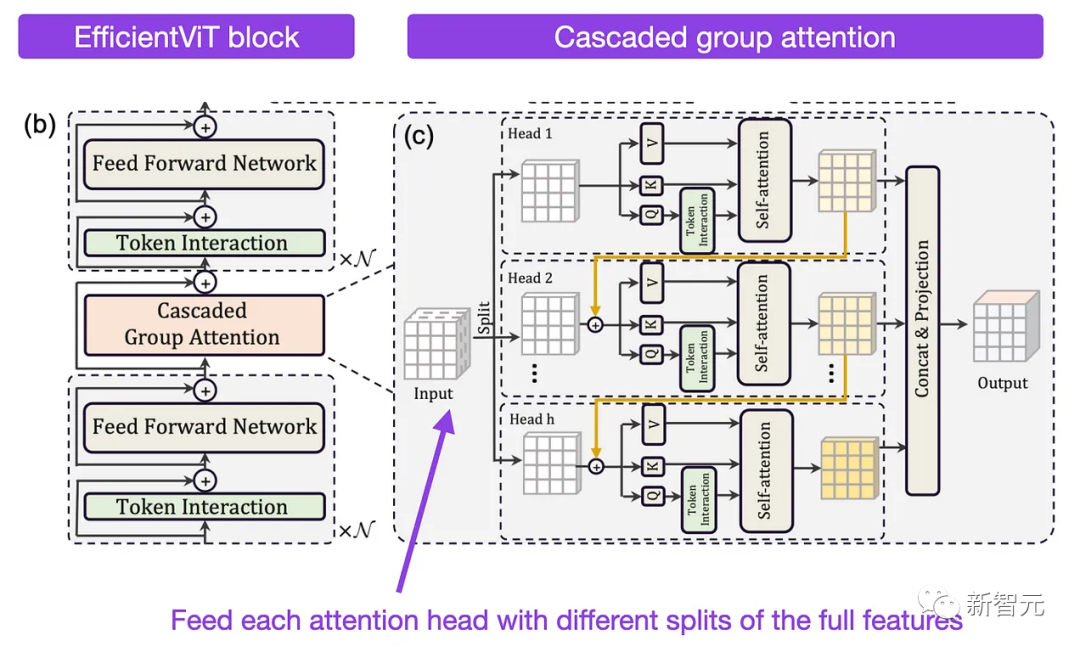
EfficientViT是一种全新的视觉Transformer,在速度和准确性之间提供了良好的平衡,其性能优于其他高效架构,如MobileNetV3和MobileViT,同时速度更快。

论文链接:https://arxiv.org/abs/2305.07027
研究人员使用级联组注意力,并为每个注意力头提供完整特征的不同分割(类似于组卷积)来减少多头自注意力层中的冗余。
之前的研究主要关注最佳的数据集大小和模型参数量,最近研究人员提出了推断计算最佳模型形状的方法,例如宽度和深度,实验中的视觉Transformer性能优于大两倍的模型。

论文链接:https://arxiv.org/abs/2305.13035
此外,如果使用相同的计算资源预算来训练较小的计算优化模型,其推理成本不到较大模型的一半。

参考资料:
https://magazine.sebastianraschka.com/p/ahead-of-ai-9-llm-tuning-and-dataset
© 版权声明
文章版权归作者所有,未经允许请勿转载。


