
斯坦福训练Transformer替代模型:1.7亿参数,能除偏、可控可解释性强
以 GPT 为代表的大型语言模型已经并还将继续取得非凡成就,但它们也存在着众所周知的问题,比如由于训练集不平衡导致的偏见问题。
针对这一问题,斯坦福大学几位研究者提出了一种新型神经架构 Backpack,宣称能够调控意义向量来干预语言模型的行为,引导语言模型输出想要的结果。该项目的代码和模型都已发布。

论文地址:https://arxiv.org/abs/2305.16765
项目地址:https://backpackmodels.science
论文一作、斯坦福大学 CS 博士生 John Hewitt 表示,Backpacks 是 Transformers 的替代,它可以在表现力(expressivity)上进行扩展,并为通过控制实现可解释性提供一种新接口。一个 backpack 学习每个字词的 k 个非上下文意义向量,从而无监督地解耦字词的预测用途。
引言
首先我们假设有前半个语句「The CEO believes that _」,我们的问题是消除神经语言模型在该句子的性别分布上的偏见。凭直觉我们就能知道该句子的性别偏见源自「CEO」一词,因为如果把「CEO」换成「护士」,偏见就会发生性别逆转。为了消除在 CEO 上的偏见,必须要对模型进行干预并且要应用到 CEO 一词所出现的所有上下文中。
理想情况下,我们希望采取的干预措施不会改变模型的上下文并且可以预测这个干预带来的影响。通常来说,从可解释性与控制的各个方面看,我们更倾向于通过一个全局应用的容易操作的接口(比如非上下文表征)来实施干预。
但对 Transformer 来说,这种干预却难以实现,因为它们的上下文表征是其输入的单体函数(monolithic function)。单体函数是指内部具有逻辑分支的函数,能够根据输入执行不同的逻辑。对 Transformer 模型的任何干预都会根据上下文情况产生复杂的非线性影响。但我们希望模型能实现丰富的精准干预,nenggou 预测在所有上下文中的情况,并依然能富有表现力;如此一来,这样的模型就能成为 Transformer 的可行替代模型。
针对这些挑战,研究者提出了一种新的神经架构 Backpack,其预测是非上下文表征的对数 – 线性组合。他们的做法是将词汇表中的每个词都表示成一组非上下文的意义向量(sense vector),这些向量表示的是学习到的该词的不同方面。
举个例子,「science」这个词的意义向量可以编码科学的类型、与技术的关系、已经得到公认的科学概念以及科学过程的不同方面(复现或实验),参见下表 1。意义向量学习的不是经典的词义,而是一个词在不同语境中的潜在作用的更一般性方面;事实上,意义向量可被视为经典词向量的一种多向量泛化。
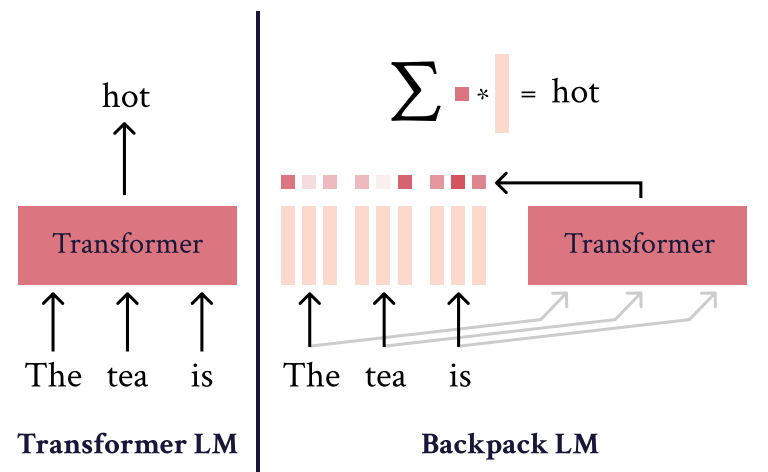
图 1 :Transformer 是序列的单体函数,而 Backpack 的输出是非上下文的、所学词的各个方面的加权和。
在干预意义向量时,为了使干预结果在不同上下文中都是可预测的,Backpack 会将一个序列中的每个词都表示成该序列中所有词的意义向量的一个线性组合。Backpack 的表现能力来自于计算该线性组合的权重的网络模型,其计算方式是将这些权重作为整个序列的一个函数。顺便一提,研究者在实验中使用的网络模型是 Transformer。由于意义向量是根据上下文大致选择的,因此它们可以专门限定到特定领域;每个意义都可以学会仅在某些上下文中才有用,并且是否有用可以预测出来。也就是说,意义对预测的贡献呈对数 – 线性模式,这意味着不管上下文如何,对意义向量的干预也同样适用(直到权重变成非负标量)。
研究者的实验表明 Backpack 语言模型确实表现力强大,并且表明对意义向量进行干预有助于解释和控制模型。在实验中,研究者在 OpenWebText 的 500 亿 token 上训练了 Backpack 语言模型;这个 Backpack 模型的上下文网络有 1.24 亿参数(意义向量有 4600 万参数),能达到一个 1.24 亿参数 Transformer 的困惑度;但如果想要更高的可解释性,就需要更大的模型。研究者还展示了如何通过意义向量来针对性地编码丰富的词义概念。
在四个词汇相似性数据集(例如 SimLex999)上的定量分析结果看,1.7 亿参数的 Backpack 的意义向量优于 60 亿参数的 GPT-J-6B Transformer 的词嵌入,并且接近针对该任务的专用方法的当前最佳表现。研究者还表明意义向量能为 Backpack 语言模型提供一种控制机制。
举个例子,对于具有职业性别刻板偏见的词(如「CEO」或「护士」),往往会学习到与该性别偏见相关联的意义向量;研究者发现通过为该意义向量降幅,能在有限环境中极大降低上下文预测中的性别差异。

表 1:左侧是表示 science 一词的意义向量示例,其中具有丰富的特定领域指向;右侧是以非上下文的方式编辑意义向量的示例(将 MacBook 变得与惠普相关),从而改变了所得的上下文预测。
Backpack 架构
下面首先将定义 Backpack 架构的一般形式,然后会证明连续词袋 word2vec(CBOW)和仅自注意力网络其实就是 Backpack 的特例。
Backpack 的一般形式
Backpack 是一个将符号序列
![]()
映射成向量序列
![]()
的参数函数,其中每个符号 x_i 都属于一个有限词汇表 V,而
![]()
。这里将 o_i 称为 x_i 在上下文序列 x_{1:n} 中的 Backpack 表征。
意义向量。对于每个 x ∈ V,Backpack 构建 k 个意义向量:
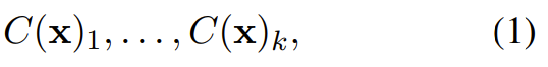
其中
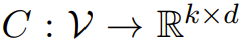
。意义向量是一种多向量,类似于 word2vec 或 GloVe 等经典的非上下文词表征。
加权和。对于一个序列 x_{1:n},元素 x_i 的表征 o_i 是词在上下文中的预测意义向量的加权和:给定上下文化权重
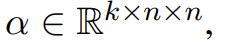
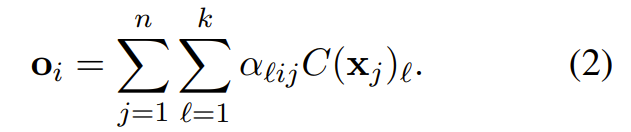
Backpack 的上下文化权重则由整个序列 x_{1:n} 的一个(非线性)上下文函数定义:
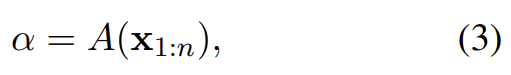
其中 
Backpack 这个名称灵感来自这一事实:backpack 是指背包,就像是一个袋子(类比于词袋 /bag-of-words),但是背包更有秩序一些。类似于词袋,Backpack 表征也是非上下文意义的加权和;但 Backpack 更加有序,因为这个加权和的权重取决于有序的序列。
Backpack 模型。Backpack 模型是一种概率模型,它将在某一输出空间 Y 上的概率定义为一个 Backpack 表征 o_{1:n} 的对数 – 线性函数:
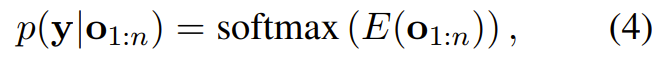
其中 是一种线性变换。因为 Backpack 模型的表征呈现对数 – 线性模式,所以意义向量对预测的贡献也呈对数 – 线性模式。这让我们可以检查意义向量,具体做法是经由 E 将意义向量投射到词汇表上,然后在任意上下文中观察其究竟会如何对预测做出贡献。
是一种线性变换。因为 Backpack 模型的表征呈现对数 – 线性模式,所以意义向量对预测的贡献也呈对数 – 线性模式。这让我们可以检查意义向量,具体做法是经由 E 将意义向量投射到词汇表上,然后在任意上下文中观察其究竟会如何对预测做出贡献。
模型的参数化可使用常用的深度神经网络,包括 LSTM 和 Transformer;这些都不是 Backpack,因为它们的输出表征是整个序列的(相对而言)无约束函数。相对而言,Backpack 的表现力看起来是有限的:其表征 o_i 是非上下文向量

以标量加权的和。序列元素之间的上下文关系只能通过权重 α 来表示。尽管如此,研究者的实验表明,一个表现能力强的上下文化权重网络可以通过意义向量的加权和来表示复杂函数,比如新提出的 1.7 亿参数的 Backpack 语言模型使用了一个 1.24 亿参数的 Transformer 模型来计算 α,并实现了和 1.24 亿参数 Transformer 语言模型一样的损失。
研究者通过数学形式证明了连续词袋与单层注意力都是 Backpack 的特例,但这里我们不再过多论述了,详情参阅原论文。
使用 Backpack 的语言建模
研究者使用 Backpack 来进行参数化,定义了一个神经自回归语言模型。对于序列的下一 token 的概率,他们使用了标准的 softmax 参数化,其中有一个将表征
![]()
映射成 logit

的权重矩阵
![]()

回想一下,Backpack 表征 o_j 是通过意义向量 C (x) 和上下文化权重 α_j 定义的。下面首先会介绍等式 (1) 中预测意义向量 C 的参数化,然后是上下文化权重网络 A 的参数化。当 o_j 是由 Backpack 参数化时,就可以称该模型为 Backpack 语言模型。
对意义参数化
对于意义函数
![]()
,我们将每个 x ∈ V 都嵌入到
中,然后将这些嵌入通过一个前向网络
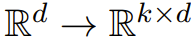
:
其中,嵌入 / 投射矩阵 E 与 (9) 式中的输出矩阵紧密关联。现在我们可以使用一个查找表来定义所有 k × |V| 意义向量,但随着 k 增大,参数数量也会变得非常大。于是研究者在这里采用的做法是将词嵌入成,然后使用共享权重将它们放大到 。这也许可以解释在不同词类型上观察到的相关意义作用。
对上下文化权重参数化
研究者使用了一个标准 Transformer 加一层多头关键词查询自注意力来对进行参数化,也就是让一个嵌入的序列通过一个 Transformer:
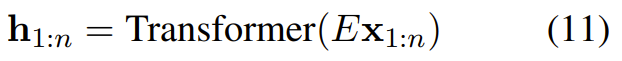
这里使用了适当的自回归掩码和某种位置表征,然后计算其中对于每个预测意义 ℓ=1,…,k 有并且矩阵。
研究者把这 k 个意义看作是头,对于每个头,上下文化权重都为对词的注意力定义一个分布。
训练 Backpack 语言模型的实验
这一节介绍了研究者为了进行验证而做的实验,其中包含训练 Backpack 和 Transformer 语言模型的超参数、数据和优化流程、评估和结果。这里我们不多介绍了,但研究者重点指出:学习 k > 1 个意义向量对于实现优良的语言建模性能而言是必需的。
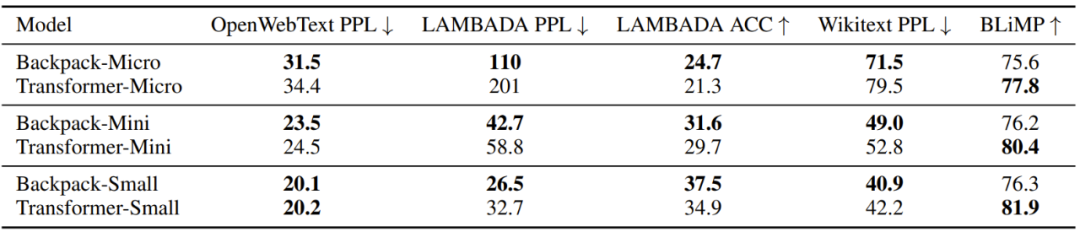
表 2:语言建模性能,所有模型都训练了 10 万步,token 批大小为 50 万,是在 OWT 上。对于 PPL 指标,越低越好;对于准确度指标,越高越好。注意这些模型的参数没有可比性;每个 Backpack 的上下文化网络中都有一个大小相当的 Transformer。
可以看出,对比每个 Backpack 语言模型以及与 Backpack 的上下文化网络的规格相当的 Transformer 语言模型,Backpack 语言模型的表现大致相当。需要指出,Backpack 的参数更多,这主要来自意义向量。研究者发现,在训练时,Backpack 语言模型的收敛时间长于 Transformer。奇怪的是,尽管 Small Backpack 和 Transformer 实现了几乎一样的 OWT 困惑度,但 Backpack 语言模型在 LAMBADA 和 Wikitext 上的表现却显著更好,同时在 BLiMP 上却又更差。
意义向量中的涌现结构
下面将通过定性和定量实验,来验证意义向量在计算词汇相似性和相关性方面的有效性。这些结果表明意义向量可以成为实施干预的高层面接口。
意义的可视化
基于实验经验,经过训练的 Backpack 模型会将特定的意义向量索引与不同的预测作用关联起来。研究者为了解释这些作用,做法是选取词 x 的意义 ℓ 并将这个意义投射到词嵌入:
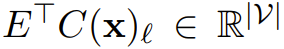
。请注意,这正是(直到一个标量)意义有助于模型的任何预测的方式。研究者是通过报告该投射下分数最高的词来解释意义向量的作用。
下表 3 可视化地展示一些意义,比如意义 12 似乎为几乎所有单词都编码了广泛的相关概念;意义 3 编码了给定 x 的二元分布的特定情况;意义 14 似乎为动词编码了相关的宾语,也为名词编码了相关的修饰词依赖子项。
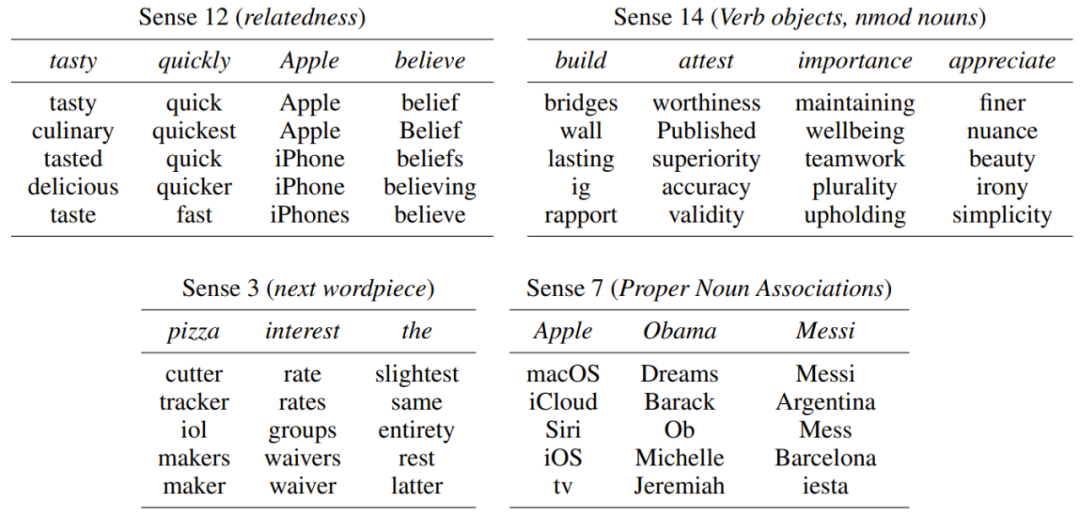
表 3:可视化地展示了在许多词上的同一意义索引如何编码细粒度的含义、相关性和预测使用情况的概念。
词汇关系测试
从下表 4 可以看到,意义 12(同义词意义)在所有数据集上都表现良好,媲美或者优于 GPT-2-1.5B 和 GPT-J-6B 等嵌入,而 GPT-J-6B 在 RG-65 上则例外。意义 14 是动词宾语意义,仅在动词相似度(VerbSim3500)上表现好,而意义的最小相似性在名词词汇相似性上表现尤其出色 (SimLex999)。这说明新提出的方法足以比肩当前最优的方法,尽管它们的训练任务非常不同,意义向量编码了大量的词汇信息。

表 4:词汇相似性评估结果。所有的数值都是 Spearman 相关度;越高越好。
用于控制的意义向量
最后,研究者通过一些具体案例进行了概念验证,即可以使用意义向量来控制语言模型的行为。
生成限定主题的内容
下图 2 中,通过 Backpack 中的意义干预来控制生成主题,对比了 Transformer 的 PPLM。

降低性别偏见
研究者发现,许多职业名词(比如护士、CEO、教师)的意义向量 10 都带有性别的刻板印象,并且这种刻板印象会通过代词连贯地表达出来。通过调降意义 10(乘以小于 1 的标量),研究者发现可以降低 Backpack 在这些职业名词上的性别偏见。

表 5:在有限设置中降低基于代词的性别偏见。

图 3:对于前半句「when the nurse walked into the room」(当那位护士走进房间),Backpack 语言模型通过将「护士」一词的意义 10 从 0(完全移除)变成 1(原始情况),条件概率分布受到的影响。
知识编辑
研究者还研究了新方法在知识编辑方面的应用。知识编辑是指编辑模型对于世界知识的预测。特别要指出,与专有名词相关的许多词都可以定位到该名词的意义向量。在定性的概念验证实验中,研究者编辑了目标词(比如 MacBook)的意义向量,移除了与另一个词(比如 Apple)的相关性,然后用再一个词(比如 HP)替代了这些相关性。可以想见,这种干预会导致 MacBook 与 HP 在预测结果中产生关联。

表 6:来自 Backpack 的样本,其中 Apple 被投射到了 MacBook 的意义嵌入之外,而 Apple 原来的位置被 HP 替代。第三个样本类似,是美式橄榄球球队和运动员相关的样本。其中加粗的部分为 prompt。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


