

一、推荐现状
先简单介绍一下推荐系统的现状。
推荐系统其实在生活中已经很常见了,随着网络上的信息越来越多,人们很难从海量信息中找出最适合自己的东西。为了解决这种信息过载的问题,衍生出了推荐系统。它会预测用户的需求,推荐其可能喜欢的内容,缓解用户做出选择的烦恼。
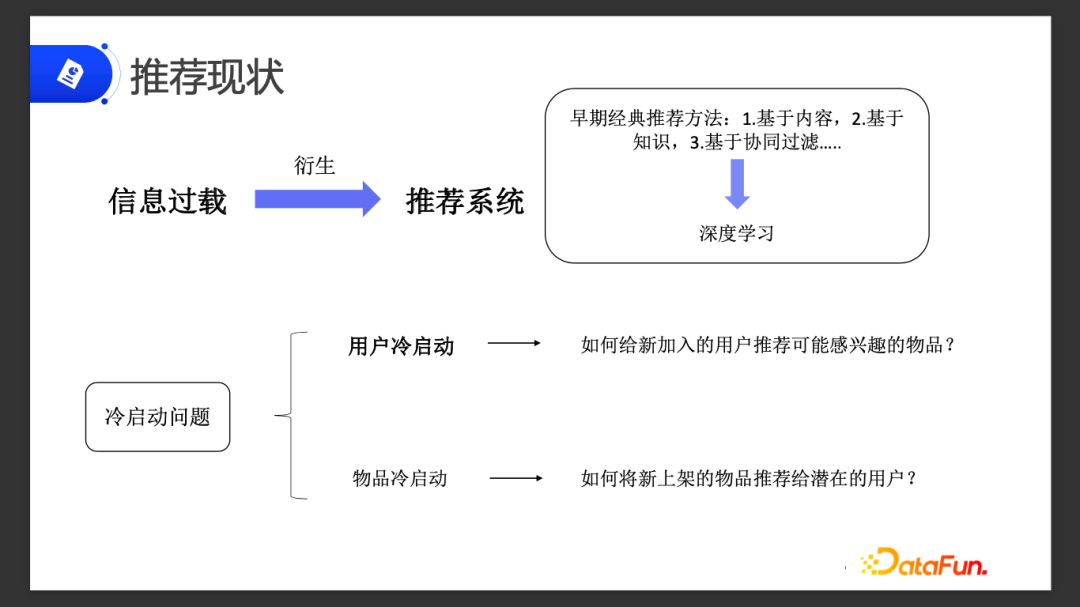
早期的推荐算法比较简单,经典算法包括基于内容的、基于知识的、还有基于协同过滤的等等。
现在的研究方向主要集中在深度学习方面,通过神经网络的训练来有效提取特征、获取更精准的表示能力,提升匹配程度。在推荐系统领域已经获得不错的效果。
上述这些方法上面都存在着一个问题,就是冷启动问题。
冷启动问题分为两类:
- 用户冷启动:如何给新加入的用户推荐可能感兴趣的物品,对于一个公司来说,用户冷启动是非常关键的,新用户的留存可以让公司发展得更快;
- 物品冷启动:如何把新上架的物品推荐给潜在的用户。
本次分享将针对用户冷启动问题来展开讨论。
二、社交兴趣网络
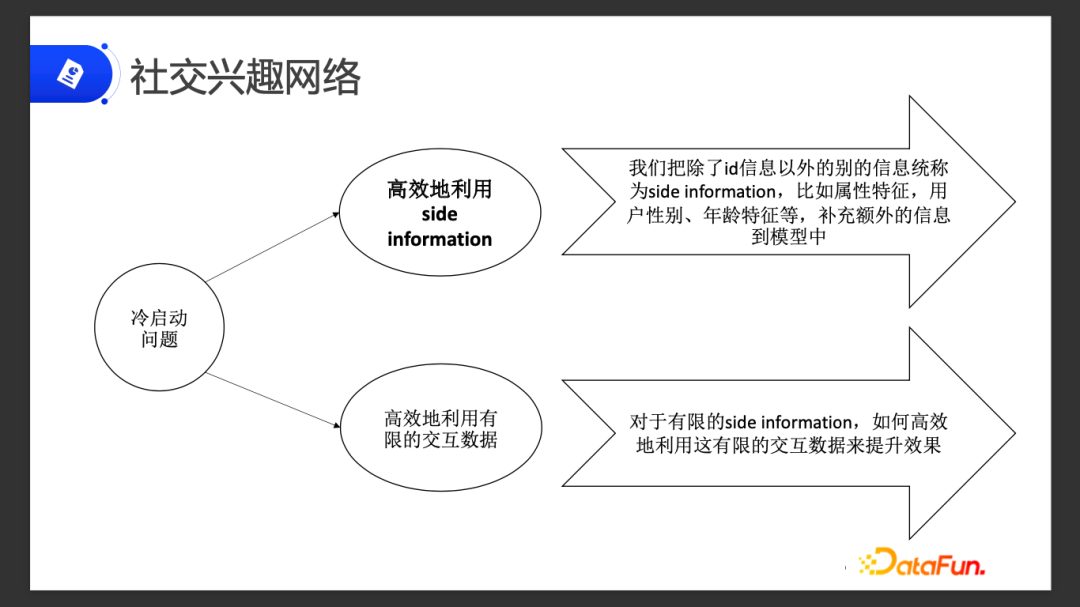
针对用户冷启动有两个解决方法:
- 首先是高效地利用 Side Information
除了 ID 信息以外,通常把用户属性特征,比如年龄、性别,还有额外的一些东西补充到模型中去训练,这是利用 Side Information 的一个方式。
- 第二是高效地利用有限的交互数据
我们没办法拿到更多的 Side Information,因此要高效地利用现有的 Side Information,来提升效果。
接下来将重点讲解如何高效地利用 Side Information。这就引出了我们今天要讲的社交兴趣网络。
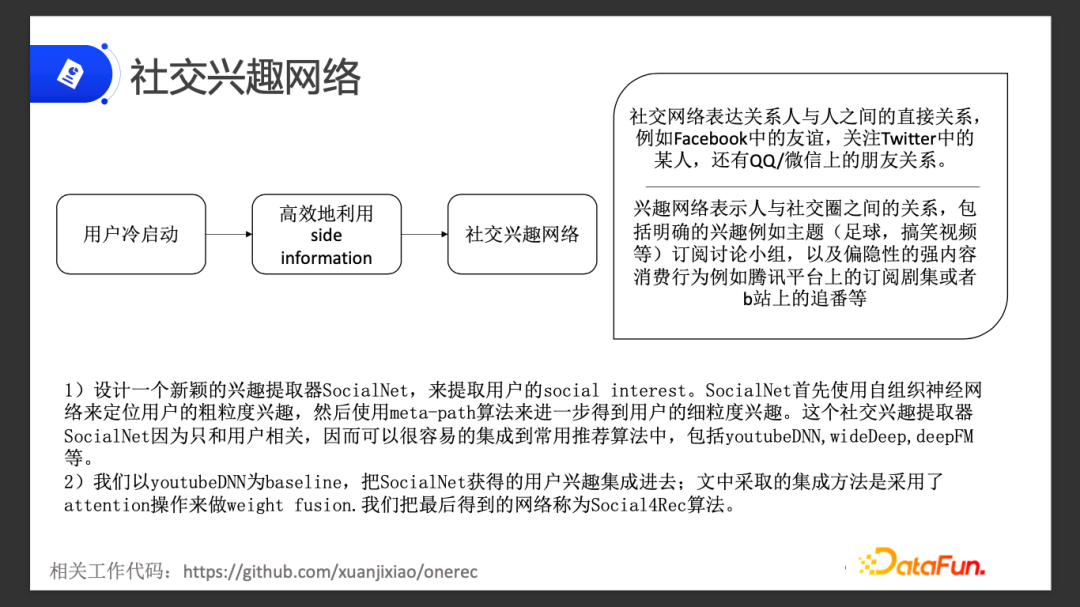
社交兴趣网络主要分为两个部分:
- 一个是社交网络,代表人与人之间的直接关系,比如 Facebook、 Twitter 、QQ等上面的好友关系。
- 另一个是兴趣网络,主要表示的是人和社交圈之间的关系,包含非常明确的,比如你经常喜欢看搞笑视频,或者比较喜欢看足球,或者是你在某些平台上面经常追哪个剧,关注哪些博主等类似的信息。
我们提出了兴趣抽取器SocialNet,来抽取用户的社交兴趣。这个抽取器是一个可集成到其他推荐算法中的非常实用的组件。在这基础上,我们选取了YouTube DNN 做 baseline,把 SocialNet 获得的用户兴趣集成进去,通过 attention 的方式来进行权重融合,得到最终的网络,叫做 Socail4Rec。下面来详细介绍这一算法。
三、Socail4Rec
1、算法模型的概览图
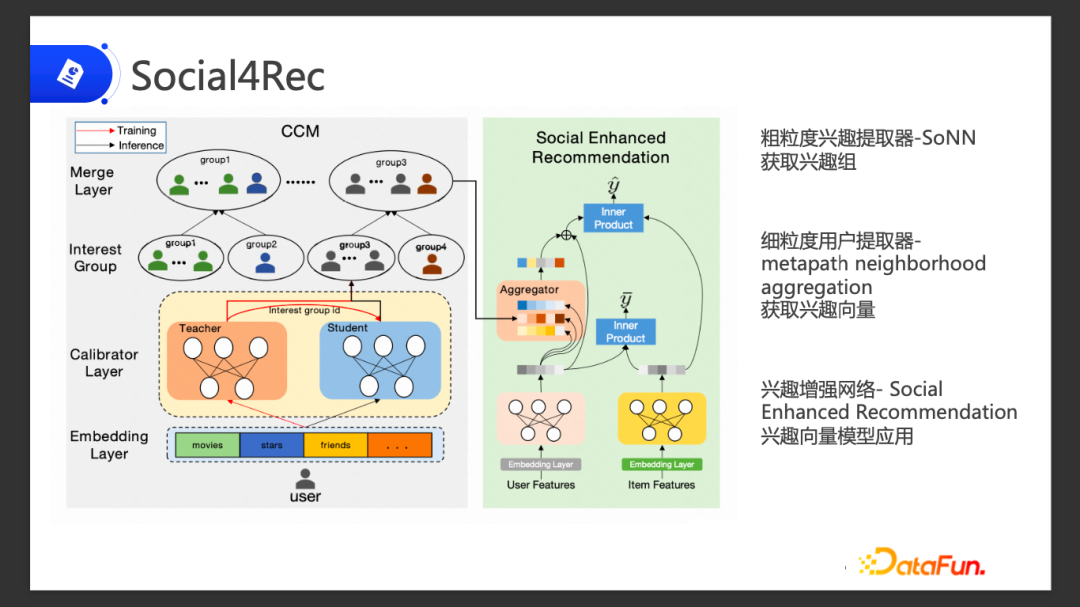
模型的总体概览图如上所示,其中包含三个部分:
- 粗粒度兴趣抽取器 – SoNN
- 细粒度兴趣抽取器 – metapath neighborhood aggregation
- 最后将抽取器集成到 YouTube DNN 模型里面去,做成兴趣向量模型应用,兴趣增强网络 – Social Enhanced Recommendation
2、Social4Rec-粗粒度兴趣提取器-SoNN

如上图,通过用户,我们可以拿到他的一些社交兴趣信息,比如他平时喜欢看什么电影,喜欢关注哪些明星,他的好友等等。针对这些信息,通过 Embedding Layer拿到其 embedding。
我们在中间设计了一个网络,叫自组织神经网络,这个网络的用途是将得到的这些 embedding 划分兴趣组,将用户归到兴趣组里面。
具体做法:
(1)第一步通过自组织神经网络,先得到它所属的兴趣组。
自组织神经网络相当于一个权重矩阵,在计算过程中会不断更新。
我们先把用户的这些兴趣特征 embedding汇到网络里面,去得出它所属的兴趣组。公式中Wj 就是自组织神经网络的可训练的权重,根据用户的embedding,去得出用户所属的最接近的兴趣组。

(2)第二步根据用户的 embedding 去更新总的用户兴趣组。
更新的方式主要是下面两个公式:把用户的输入去计算出跟整个矩阵组的差值,根据学习率和衰减系数得到更新权重。衰减的系数可以根据公式算出来的。Sj,i 就代表当前兴趣和我们需要计算的另一个兴趣的距离,来得出它所属的范围:
- 如果距离是0:我们以最大权重更新,相当于在矩阵里面可能有 100 个兴趣,如果用户算出来的上一个方法里面的兴趣跟当前兴趣是同一个兴趣,我们就以最大的权重去更新。
- 如果有不一样的距离:我们就根据公式算出它的衰减系数。
- 如果距离太远:我们就直接不更新它的权重。
更新权重的方式,在经过几次迭代之后可以更新成一个比较合适的权重矩阵,也可以对每一个用户区分出他的兴趣组。在这个过程中,我们就可以把用户区分到兴趣组上面。

(3)第三步兴趣组聚合
兴趣组可能会存在一些情况,太稀疏,每个组里面的人可能很少。我们需要通过 KMeans 的方法,把这些比较稀疏的兴趣组进行小小的聚合。比如可能足球细分类里面又有很多的小类。这些小类的兴趣组里面的用户并不多,我们就需要把他们重新聚合成一个大类,将用户重新归到大的兴趣组里面。
在这一步我们就把用户进行了一个粗的分类,分到了比较大的兴趣组里面。
3、Social4Rec-细粒度兴趣提取器-Meta-path neighborhood aggregation
第二个就是进行细分类,通过粗分类我们已经把用户群体归到大的组里面,但这个组会比较大。要在这个大的组里面更精细地去抽取用户的兴趣向量,我们采用了Meta-path 的方法去抽取。
一个典型的 Meta-path UMU 定义为:比如用户订阅电影, User 1 订阅了 Movie 1, User 2 也订阅了 Movie 1,通过 Meta-path 他们两个是可以关联起来的。通过这样的方式,在同一个大的兴趣组里面,我们可以找到这样user1具有关联性的很多个user2用户,我们抽取其中的 top N 的user2用户进行 embedding 的聚合。
top N的用户怎么选取?
直接把它们的初始 embedding 与当前user的embedding算 距离最近的top10,然后将这个 top10 聚合到 user embedding 上面去。

这是具体的计算公式,在兴趣组里面,通过 Meta-path 的方法找最近 top k 的用户,将这些用户的 embedding 聚合起来,再加上自己用户本身的embedding,得到最终的细粒度的用户的 embedding。
因为我们初始的时候是有通过多种兴趣,电影、关注的明星、Up 主、朋友这 4 种关系,所以我们有 4 个 Meta-path 的方法,分别得出了 4 种 Meta-path embedding。每个方式通过聚合自己的embedding、top N 个的邻居 embedding 的向量,得到 4 个 Meta-path 的embedding。最终我们拿这 4 个兴趣向量 embedding 聚合到初始的 YouTube DNN 模型上面。

4、兴趣向量聚合
我们的聚合方式:
- 首先我们输入用户特征到 YouTube DNN 模型里面,得到 Input DNN 的 embedding,
- 分别对4 种兴趣向量做 attention ,会得到这 4 种兴趣向量的权重。比如用户本身属性特征过完 YouTube DNN 之后,得到一串 embedding,发现是比较喜欢看电影的,可能对于电影的抽出来的兴趣向量的权重就会比较高。如果对于明星或者对于朋友这种关系比较重,那么它们各自的权重肯定会更高。
- 通过这种方式得出每个兴趣的权重向量,再通过权重融合,得到用户最终叠加的兴趣向量的权重融合的 embedding,再跟 item 的 embedding 进行内积,得到最终的 CTR 分数。
简单来说,就是把用户兴趣直接 concat 到用户表达上做 attention,之后再经过 MLP 层得到 embedding,然后跟 item 做内积,得到CTR。

这个方式在我们之前的数据集上得到了有效的验证。
之前数据集主要是两个,一个是社交的图, star 代表有多少用户关注明星的 UA 对的数量。Movie 就是用户观看电影的数量。
下面这个是我们主要用的数据集。我们抽取了 15 天的在线的流量日志,前 14 天用于训练,最后一天用于测试。其中区分了冷启动用户的数据,用于单独在冷启动用户上验证效果。
5、总体的效果

总体的效果可以看上图的消融实验数据。
离线部分,在全部用户上面从最初的单独用 YouTube DNN 模型的AUC 0.765,提升到了 0.770。在冷启用户上面的提升更多,将近 2.33 个百分点。
这四个消融实验中三个对照实验代表的含义分别为:
- 第一个是代表不带粗粒度提取器的版本
- 第二个是不带细粒度提取器的版本
- 第三个是不进行 Attention,而是直接将兴趣特征拼起来平均聚合。
在线部分,我们在所有用户上面去统计了一下,在线CTR提升了 3.6%,在冷启用户上CTR提升了 2%,在点击数量和观看时长上面都分别有比较大的提升。其中冷启用户的提升更多。所以在解决冷启用户问题方面,我们的模型显现出来比较显著的效果。
四、总结
在item推荐中,学术界、业界典型的工作都是如何更好地提取用户直接交互行为信息,而忽视了在真实平台上我们存在的各种各样的信息。Social interest信息在推荐算法中的实用性,这对于在推荐平台上做算法的同学应该是一个特别好的启发,因为我们平台上存在大量的社交信息,有效地利用这些信息将为我们的各种业务带来极大的提升。
五、Q&A
Q1:Meta-path 的定义很大程度决定效果,而 Meta-path 的组合种类很多,怎么根据产品选择?
A1:我们线上拿到了4 种类型的兴趣向量,对于这4种类型,我们分别定义了 4 种 Meta –path,因为根据类型的定义,我们已经很明确,可以得到的只有这 4 种的类型组合。个人认为可以根据当前数据的提供形式来决定到底用什么样的 Meta-path组合,因为在我们的实验当中是很明确的 4种用户可以关联起来的方式,所以我们直接是用的 4 种的,根据电影、明星、关注的 Up 主、好友这四种关系去组合 Meta-path。
Q2:聚类的个数有什么方法确定吗?
A2:聚类的个数,其实刚开始是拍的,主要还是通过调参的方式去判断出聚类数,自组织神经网络聚成一些小类,最开始是定义得比较大的,在大了之后再用 KMeans 去减小它的个数,中间是通过去调整得出来的,其实还主要是超参,超参是调试出来的。
Q3:有没有分析为什么冷启动用户效果更好?
A3:在一个 YouTube DNN 模型里面,冷启动用户能拿到行为序列特征是非常少的。在这种比较少的特征上面,我们抽取出来的社交兴趣的Embedding 是相对比较重的,起到的作用就比较高。所以在冷启动用户上面,我们单独加这个模块效果是更好的。
注:相关代码和论文链接:https://github.com/xuanjixiao/onerec。
关于OneRec
在常规推荐系统算法和系统双优化的范式下,一线公司针对单个任务或单个业务的效果挖掘几乎达到极限。从2019年我们开始关注多种信息的萃取融合,提出了OneRec算法,希望通过平台或外部各种各样的信息来进行知识集成,打破数据孤岛,极大扩充推荐的“Extra World Knowledge”。已实践的算法包括行为数据(多信号,长短期信号),内容描述,社交信息,知识图谱等。在OneRec,每种信息和整体算法的集成是可插拔的,这样的话一方面方便大家在自己的平台数据下灵活组合各种信息,另一方面方便开源共建,大家可以在上边集成自己的各种算法。OneRec分享的都是之前在线上验证过效果的工作,相关代码和论文已经开源在:https://github.com/xuanjixiao/onerec 。
OneRec系列算法目前已经发布的算法:
(1) OneRec1_NeighbourEnhancedDNN 行为和内容两种信号的强化建模。增强用户/item的表达和他们的交互。
相关文章:后续在OneRec主页放出。
相关论文:Neighbor Based Enhancement for the Long-Tail Ranking Problem in Video Rank Models , DLP-KDD 2021。
(2)OneRec2_Social4Rec 行为/内容之外使用social interest信息。增强用户的表达,有效融合行为,内容,社交兴趣三种信号。
相关文章:后续在OneRec主页放出。
相关论文:Social4Rec: Distilling User Preference from Social Graph for Video Recommendation in Tencent。
论文链接:https://arxiv.org/pdf/2302.09971.pdf。
(3)OneRec3_SparseSharing 如何更好的利用点击信号和转化信号。通过彩票理论实现神经元级别的多任务学习,进一步优化cvr的效果。
相关文章:《OneRec4_LT4REC:基于彩票假设的多任务学习算法》。
相关论文:LT4REC: A Lottery Ticket Hypothesis Based Multi-task Practice for Video Recommendation System。
论文链接:https://arxiv.org/abs/2008.09872。
[后续] 2023 CVR多任务工作:Click-aware Structure Transfer with Sample Weight Assignment for Post-Click Conversion Rate Estimation, 2023, ECML-PKDD。
[前序] 2018 CVR多任务工作:Calibration4CVR:2018年关于“神经元级别共享的多任务CVR”的初探-2018。
(4)OneRec4_SessionLTV 对于一个session浏览过程,结合短期reward和长期reward,通过强化学习来建模用户价值,从而找到LTV价值更高的结果给到用户,在视频场景和google RL simulator上均有正向效果。
相关论文:On Modeling Long-Term User Engagement from Stochastic Feedback。
论文链接:https://arxiv.org/pdf/2302.06101.pdf, WWW 2023。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


