自动生成电路想法源自图灵老师邱奇,被称为编程语言圣杯。
而人工智能驱动的芯片自动设计,更将是一场设计界的革命!
前段时间,纽约大学 Chat-Chip 项目,引爆热潮。与此同时,中科院计算所在 arXiv 发布 ChipGPT 工作,两队人马争先后,只相差一日!
这场「人工智能芯片大战」激战正酣,各施法宝,令芯片业翻手为云,覆手为雨。
即便短期内人工智能难完全取代人工,但人工与人工智能联袂设计,相得益彰,必将极大增强芯片设计生产力与创新力,关系到芯片设计之未来!
 图片
图片
论文地址:https://arxiv.org/abs/2305.1401
杜克大学陈怡然老师在微博上表达了对芯片自动生成领域的关注,认为这个话题令人振奋,而中科院计算所 ChipGPT 也同样引人瞩目,但是想要真正做到自动化芯片生成还有很长的路要走。
ChipGPT 作者的指导老师王颖博士认为,现有的工作只是初步评估了大语言模型交互式芯片设计的潜力,如何将其融入现有EDA流程实现无人值守芯片设计将成为下一个目标。
 图片
图片
陈教授这里提到的 ChipGPT,虽然同样也是基于大语言模型的自动设计芯片,但与 Chip-Chat 不同,中科院计算所提出的 ChipGPT 还探索针对芯片性能和面积的优化方法。
不仅如此,ChipGPT 还在芯片设计上,比 ChatGPT 节省了多达 47% 面积。
大模型芯片设计 PK 战:Chip-Chat vs ChipGPT?
虽说这两篇工作都借大模型力量生成芯片,见识广阔,一览众山小。但目前人工智能还处在发展初期,后续工作仍浩浩荡荡。
对此,ChipGPT 作者称,要大模型玩转芯片自动设计,三大难题迫在眉睫:
第一个问题是,我到底要往模型的对话里塞什么玩意儿?芯片设计涉及的知识太过广博深奥,要把所有内容都嘟嘟嘟往模型的上下文里塞,下场恐怕和「狗熊掰苞米」一样,统统忘光光。如何精选模型的「餐饮内容」, 这可是个让芯片设计师们头发都白了的难题。
第二个问题是,如何通过「Prompt Engineering」让这个大模型生成出来的芯片更好更强大?要知道,Prompt Engineering 本身就是一门高深莫测的玄学,让大模型一下子领会,简直难上加难。
第三个问题是,如何控制大模型生成出来的 HDL,让设计出来的芯片在性能、功耗和面积之间达到最佳的平衡?任何芯片都面临这三者之间的博弈,要让大模型自由自在地搞定,简直是痴人说梦。
要是能爬得过这「三座大山」,芯片自动设计的未来可就指日可待了。不过话又说回来,就算解决了这三个问题,真正产业化可还遥遥无期呢。
所以呢,芯片设计师们暂时还是放心吧,你们的饭碗短期内应该还是很稳的!
芯片合成实力之源泉,大模型输入有何高深玄机?
HDL = ChipGPT(Specification)
HDL = Chat-Chip(Prompt List)Chip-Chat 纯聊天输入难定制所需,ChipGPT 研究从芯片规范说明抽丝剥茧入手!
Chip-Chat 聊天玩自由来去无踪迹,ChipGPT 一丝不苟只信规范说明(Specification)指点迷津。虽聊天可研究发挥,生产更凭规范保证准确。
故 ChipGPT 研究从规范说明着手,将其放入聊天、试图直接应用芯片规范说明,却发现难题重重:
第一,从规范说明提取会得大量无用信息,如模块运行错误模式与复杂时序等等。大模型收费看 token 数,所以更应从规范说明中精炼有用信息。
第二,芯片规范说明混乱无序,GPT 自动提取难保生成准确。故 ChipGPT 选择手工提取,建立规范说明表格,将输入归于表格信息。
基于芯片说明书与基于简单提示,ChipGPT 与 Chip-Chat 应用场景天差地别!
ChipGPT 研究目标与基于提示的 Chip-Chat 大相径庭。
ChipGPT 旨在为研究者提供整体框架,指导大模型芯片硬件自动生成。Chip-Chat 则在告诉研究者大模型给硬件自动生成带来何种新挑战与机遇。
故 ChipGPT 可谓指南书,引导工程师与研究者遨游大模型芯片合成之道。
ChipGPT 为芯片自动生成研究提供指南,想玩转大模型芯片设计者可从中「取经」。它从芯片规范说明提取入手,避免大模型直接处理规范说明种种负面影响。手工建立规范说明表格,将输入信息归类,较好解决大模型处理不规则信息难题。
相比之下,Chip-Chat 是大模型在硬件自动生成领域新尝试,更似让研究者知悉大模型给该领域带来机遇与挑战,属测试探索应用。故两者虽同大模型自动生成芯片研究,应用场景与目的差异颇大。
 图片
图片
终结玄学!ChipGPT 让 Prompt Engineering 逐渐「可控」
基于规范说明的输入也会分解为小的提示,但在芯片生成中,不规则的提示会带来一些问题:
1) 大模型自动设计芯片,输出结果可重复性与稳定性堪忧!
如图 7 所示,大模型玩转芯片设计,生成的代码稳定性是一个大问题。就算给同样的提示,它生成的 Verilog 代码也常常会「前后不搭调」,影响生成结果的可重复性和稳定性。
这可让想用大模型自动设计芯片的人又爱又恨,成了这一路上最大的绊脚石。
要解决这个难题,使用确定的 Module 接口是个不错的办法。明确接口后,大模型处理输入的不确定性就可以大幅减少,生成结果的稳定性自然也会提高。
这就像家长提前告知孩子作业要求一样,大模型事先知道需遵守的「规矩」,自然也能高效稳定地完成「作业」了。
2)芯片连接信号,如何解开这段全局最难理清的「头疼之链」?
大模型一口吃个胖子,不利于身体健康。同样,使用一个提示同时处理多个限制,会让大模型生成的代码质量大打折扣。
就像人吃饭一样,一次吃太多会造成消化不良。大模型也一样,一次处理太多限制,容易搞混导致输出错误。
图 8 中,若把额外信号限制也放入同一个提示,大模型处理起来难免手忙脚乱,就会对芯片设计的正确性造成极大影响。
相比之下,如果把额外限制(如 Ready-Valid 信号)提取出来,放到下一轮的提示中,大模型就能逐一轻松地「消化」,然后才能正确地合成接口。
这就好比人吃饭时,分多次适量地吃,而不是一口气吃太多,更有利于消化吸收。
所以,对大模型来说,尽量避免一次处理过多限制是一个简单高效的原则。要想让它生成高质量的代码,最佳方法就是分步骤输入,不要一次「塞」太多需考虑的因素。
对芯片自动设计而言,提取额外限制,分步骤通过多轮提示输入,可以较好地解决大模型处理多个限制带来的难题,让其有条不紊地完成设计任务。
 图片
图片
3)大规模模块生成,要实现自动设计的「胜在规模」效应,仍需跨越几道坎?
要让大模型自动生成大规模模块,直接使用整个大模块的描述输入,效果可能会「一塌糊涂」。这就像让孩子直接处理整本教科书一样,势必会被难度「吓倒」,无从下手。
相比之下,从小功能模块开始,逐步组合生成大模块,可以避免难度过大带来的问题。这就像教科书分章节讲解一样,让读者循序渐进,逐步掌握。
ChipGPT 使用的「从小到大」方法,先从小模块功能入手,逐步使用一系列提示代替单个提示,组合生成大模块,避免了直接处理大模块描述带来的问题。
所以,对大模型自动化生成大规模模块来说,使用「循序渐进」的方法至关重要。直接处理整个大模块的描述,难度和复杂性都太大,很难取得好结果。
而通过从小功能模块开始,逐步组合和输入,让大模型逐步掌握并生成大模块,可以较好地避开这一难题。
这其实也是人工智能发展的一般规律,通过避免一次处理过高难度的任务,选择循序渐进的训练和生成方法,可以最大限度发挥人工智能的学习和生成能力。
对芯片自动设计而言,要实现大规模模块的自动生成,采用 ChipGPT 的这种「从小到大」的方法,从小功能模块开始组合输入,逐渐生成大模块,无疑是一条较为可行的路径。
 图片
图片
甩锅大模型无济于事,PPA 平衡终究需靠一己之力?
大模型虽然聪明,但生成代码质量不比人工,这也是研究工作面临的最大难题。
一般来说,基于 GPT 的设计依靠反馈迭代,但现有反馈方式只关注功能,很难生成考虑性能、功耗和面积的芯片。
ChipGPT 的作者意识到这一短板,所以加入输出管理器以管理反馈,及时优化芯片的 PPA。
这就像老师不仅检查作业的正确性,还关注字迹、表达等方面一样,可以帮助学生在更广泛的方面提高。输出管理器就相当于老师,不仅检查功能性反馈,还关注 PPA 等方面,及时提醒大模型进行改进。
所以,对大模型自动化设计芯片来说,仅靠功能反馈是不够的,还需要考虑 PPA 等方面,以生成全面优质的设计。
单纯依靠大模型自己完成这一任务难度较大,容易忽略某些方面。而加入输出管理器可以有效弥补这一不足,及时检查 PPA 等指标,让大模型得到全面反馈,以生成更加优质的代码。
 图片
图片
大模型自动设计不止局限于生成一种设计方案,它可以产生多种方案供选择,这给研究工作带来更大灵活性。
ChipGPT 通过加入后端组件,每轮可以生成不同代码,然后使用枚举法选择最符合目标的代码,这种方法比 GPT 单纯随机输出的效果要好很多。
就像 GPT 自动生成的矩阵乘法电路,虽然实现同一功能,却可以产生不同方案,在时间延迟和面积之间作出权衡。
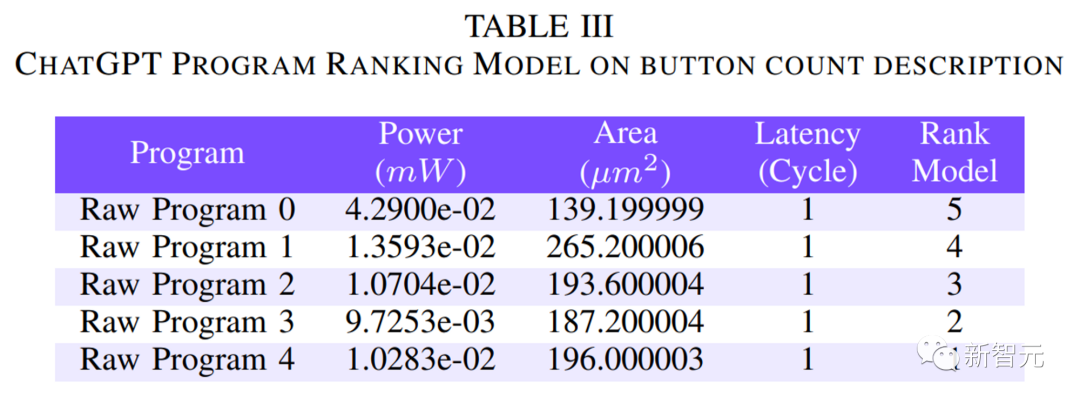
利用这一优势,可以产生不同版本的代码,如表 3 所示 button-count 产生 5 个程序,通过检查后,面积不同。
表 4 显示如果按不同标准选择,最终输出也不同。
 图片
图片
所以,ChipGPT 这种加入选择机制的方法,可以根据不同目标选择最优方案,显著提高效果。
如作者提到,如果目标是最优面积,与不加入反馈方法相比,面积优化率可以达 47%。
这表明,大模型自动设计不应局限于生成一种方案,加入选择机制可以产生更优设计。
 图片
图片
ChipGPT 这种每轮生成不同代码,然后选择最符合目标的方案的方法,可以发挥大模型产生多种方案的优势,获得更优设计方案。
对研究人员来说,这不仅为大模型自动化设计芯片提供了新思路,也说明选择机制在发挥大模型潜能方面作用巨大。
自动设计并不等同于盲目生成,加入选择机制可以让大模型在自动设计的同时达到优化目标,这是实现高质量设计的关键因素之一。
芯片设计方法之争,ChipGPT 竟力压群雄?
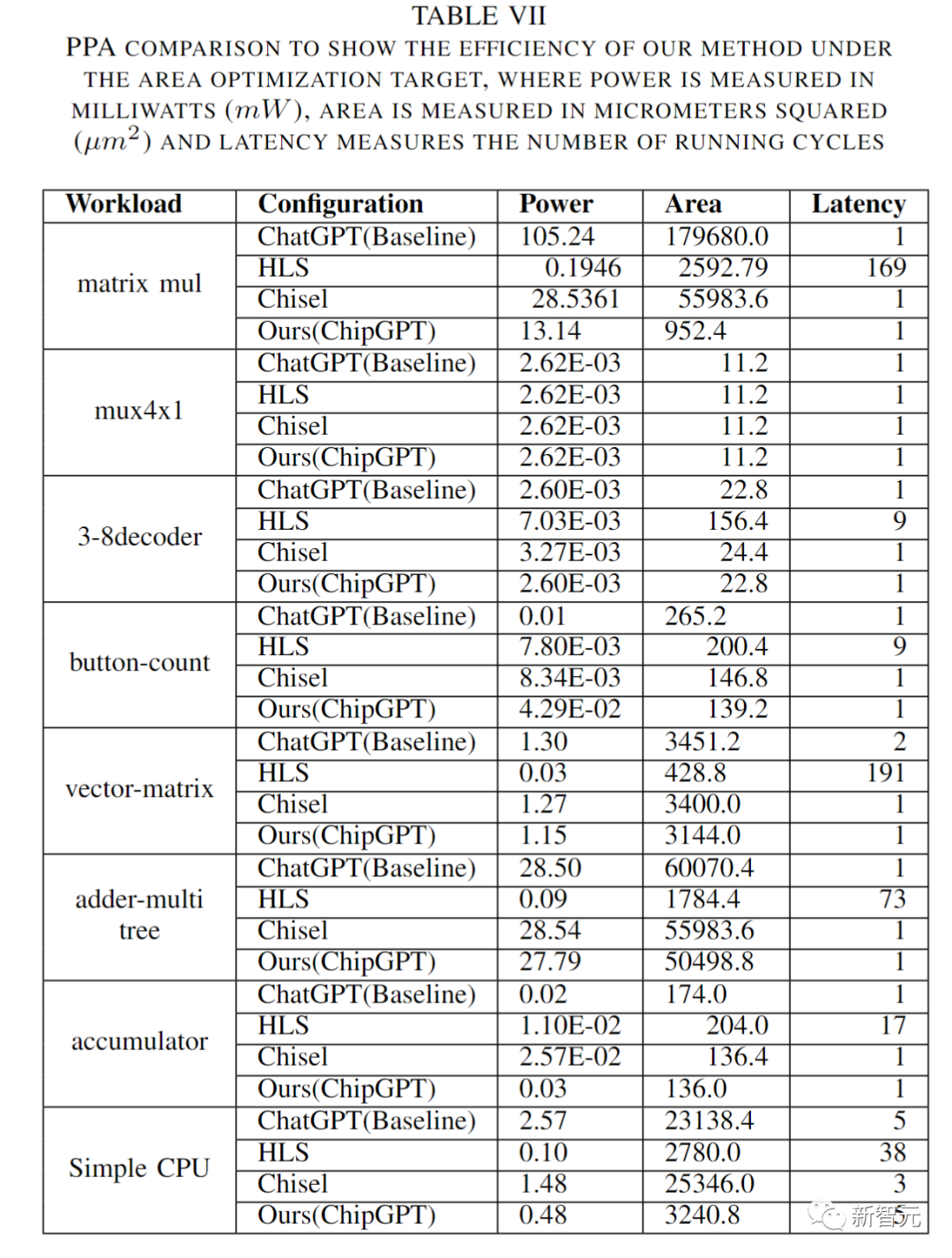
ChipGPT 的结论表明,与传统敏捷方法相比,代码量可以减少 5.32-9.25 倍。利用大语言模型,ChipGPT 可以显著加速芯片开发。
在优化面积模式下,ChipGPT 的面积减少最大可达 47%, 比原始 ChatGPT 模型减少更多。它还将大语言模型的正确性从概率正确提高到规则正确。
简而言之,ChipGPT 让芯片开发速度飙升,效率大幅提高。与传统方法相比,编码量少了 5-9 倍,这意味着开发周期可以缩短很多。利用大语言模型,ChipGPT 让芯片开发一下子就「升级」了。
 图片
图片
在优化面积方面,ChipGPT 也有亮眼表现,最大可以减少 47% 的面积,比 ChatGPT 原始大模型减少更多。这说明在自动化设计的同时,ChipGPT 还可以实现较高的设计优化。
另外,ChipGPT 还提高了大语言模型的正确性,从概率正确提高到规则正确。这意味着大语言模型的输出结果更加准确可靠,而不仅仅依靠概率。
所以,总体来说,ChipGPT 在三个方面取得重要进展:
1) 大幅提高编程效率,编码量减少 5-9 倍,芯片开发周期大幅缩短。
2) 实现较高设计优化,面积减少最大 47%, 优于 ChatGPT 模型。
3) 提高大语言模型的正确性,从概率正确到规则正确,输出结果更加准确。
这充分证明了大语言模型可以促进芯片开发自动化,并在自动化的同时实现设计优化。这为大语言模型应用于更广泛领域,特别是产业化应用提供了理论基础和实证依据。
芯片自动生成难辨优胜,评价标准来破迷局!
ChipGPT 从三个角度评价芯片自动生成方案:
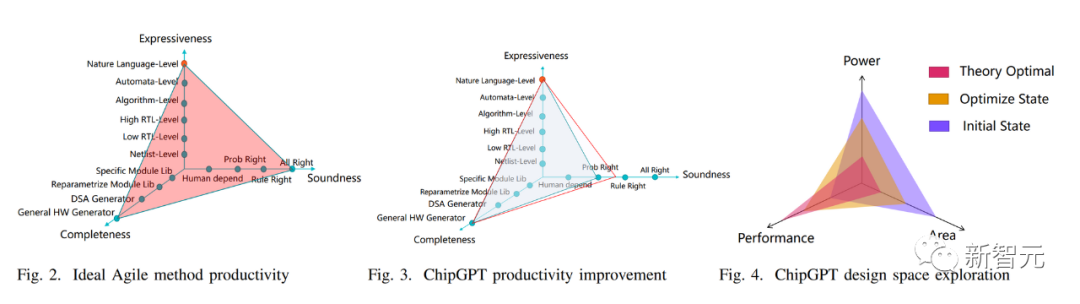
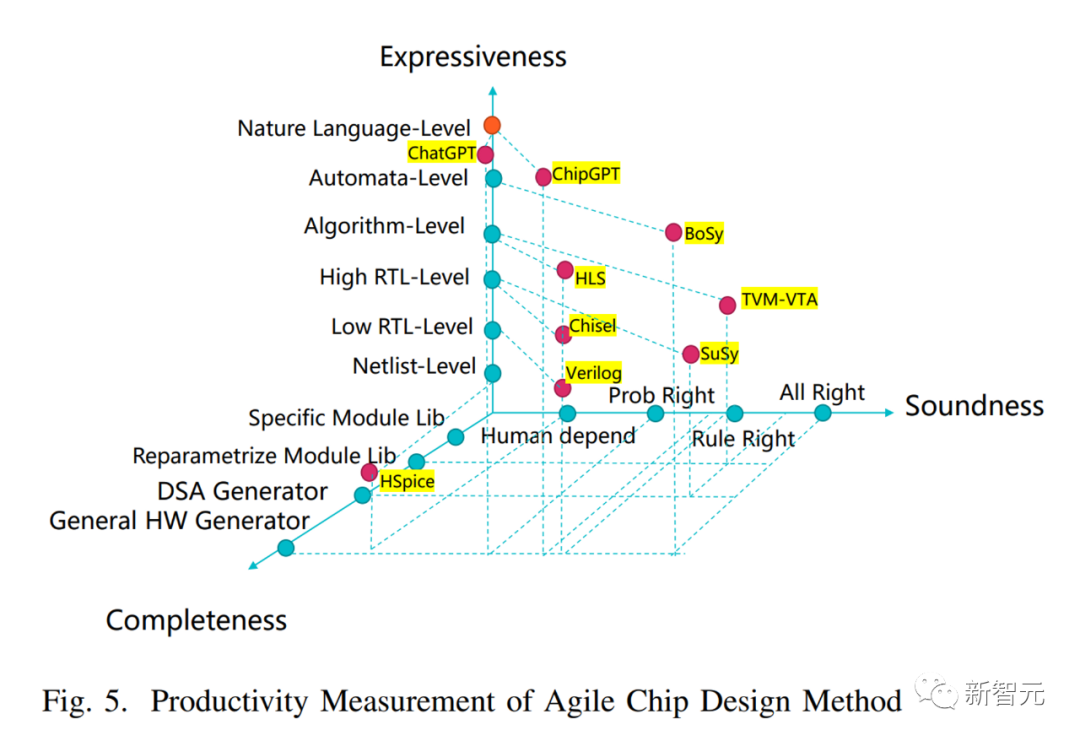
1) 正确性:生成的硬件描述是否正确。ChatGPT 和 ChipGPT 属于概率正确。
2) 完备性:方法覆盖的设计空间范围。ChatGPT 和 ChipGPT 属于通用硬件生成器,可以描述各种规模和类型的逻辑。
3) 表达能力:输入语言的生产力。ChatGPT 和 ChipGPT 使用自然语言,属于最高级。
 图片
图片
所以,总体而言,ChatGPT 和 ChipGPT 在三个维度上属于概率正确、通用硬件生成器和最高表达能力。这意味着它们可以概率生成正确的各类硬件描述,并且输入方法属于最高生产力的自然语言。
这为比较不同芯片自动生成方法提供了较全面客观的评价体系。对研究人员和相关企业来说,这有助于选择最适合的方法,发挥最大效益。
 图片
图片
总之,要实现芯片自动生成的产业应用,选择最优方法至关重要。
ChipGPT 提供的这套评价体系,为做出最佳选择提供了较为客观的判断依据,这无疑也有利于相关技术的产业推广。
所以,这些成果在一定程度上也为大语言模型等新技术的产业化应用奠定基础。
下一步:无人值守的 AI 自动化芯片设计是否可能?
Chat-Chip 和 ChipGPT 已经证明了大语言模型在 RTL 设计方面所具备的巨大潜力,而考虑到大语言模型通常由包括代码在内的大量且丰富的文本语料训练而成,其知识储备远不止可以用来实现RTL设计,我们观察发现其对芯片设计过程中的其他任务也有着一定的解决能力,例如根据 EDA 工具的 report 给出优化 PPA 的思路、甚至设计 specification 等。
此外,已有的工作如 AutoGPT、ChatGPT Plugins 等进一步证明了大语言模型具有任务分解、操作工具的能力,因此,一个自然的想法是能否让大语言模型驱动完整的芯片设计过程:即自主分解用户给出的由自然语言描述的芯片 / IP 设计需求、设计 specification、实现 RTL,并进一步通过与 EDA 工具交互实现调试和 PPA(性能 / 功耗 / 面积)优化,最后得到物理版图。
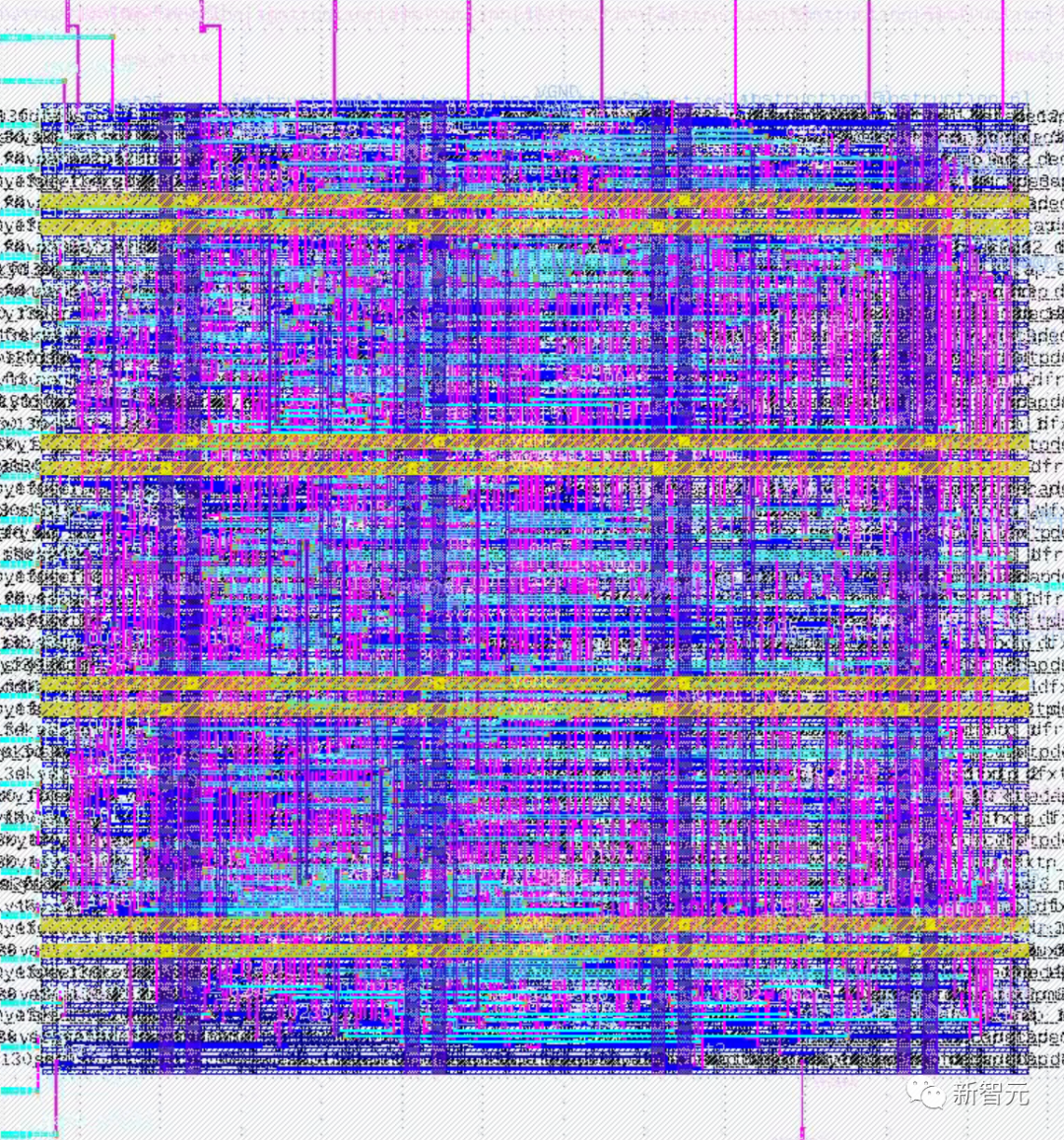
为此,基于 ChipGPT 的自动化框架ChipGPT2.0已经搭建了这样的一个原型,相比需要设计人员持续交互并处理反馈(Human-in-the-loop )的 Chat-chip 方法,ChipGPT2.0 可以初步完全自主设计 UART 控制器、8 位 CPU、RISC-V CPU 等常见的组件,所得到的设计具有一定的可用性,也就证明了无人值守的 AI 自动化芯片设计是可能的。
当然,正如前文所说,基于大语言模型的设计仅达到了概率正确,我们搭建的原型也并不是每次都能得到完全工程可用的实现,但我们相信这样一套自动设计方法是对传统的基于手动设计方法的重要补充。
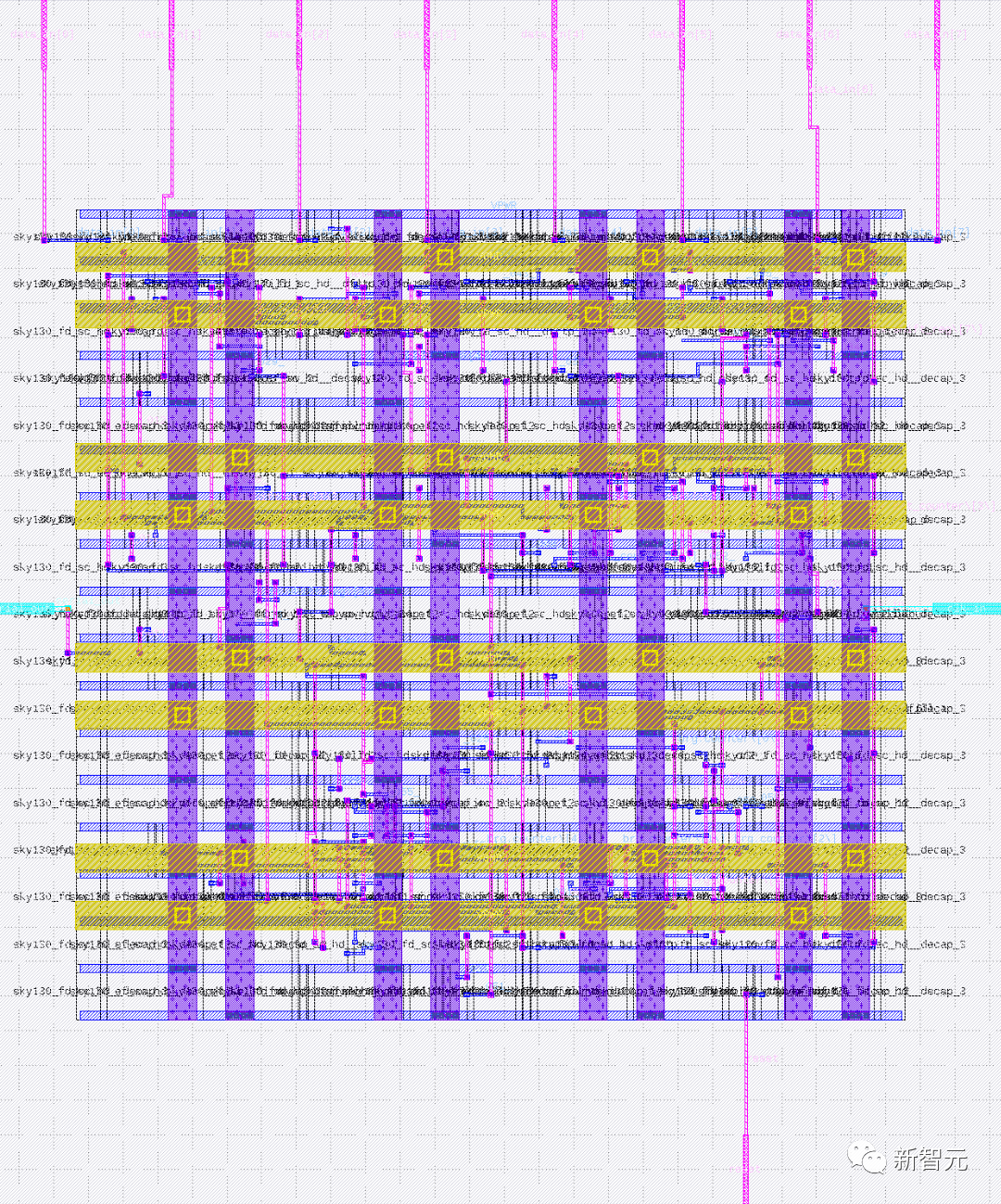 大语言模型完全自主设计的UART控制器版图
大语言模型完全自主设计的UART控制器版图
 图片
图片
大语言模型完全自主设计的8位MCU版图
 大语言模型完全自主设计的RISC-V CPU版图
大语言模型完全自主设计的RISC-V CPU版图
大语言模型是不是芯片自动生成的华山之路?
相比采用自然语言与大模型辅助设计的方法,程序合成的方法可以提供更高的方法鲁棒性和稳定性。
这方面的代表性工作有中科院计算所智能处理器研究中心提出的自动化CPU设计方法,该方法以程序合成为中心,利用输入输出对(IO Examples)可以直接生成网表级电路。
这种方法的准确率高,该方法设计的 CPU 自动生成准确率近 100%,理论上通过扩增测试用例可以达 100% 功能正确。
所以,总体来说,相比大语言模型,该方法在以下两点上更具优势:
1) 无需人工干预和反馈。
目前大模型更多还是基于现有的流程做辅助设计,这个工作无需人工参与反复迭代的逻辑设计和验证环节,从 IO 直接到电路,做的是全自动设计。无需专家工程师提供形式化的代码(C、Chisel、Verilog)或者非形式化的自然语言描述。
2) 符号方法的准确率更高。
如基于输入输出对的符号方法理论上可以达到 100% 的准确率,更适用于处理器等设计。但大语言模型也具有优势,如更通用、生产力更高等。
所以,选择何种方法更适合,还需要根据实际应用场景和需求判断。对研究人员和相关企业来说,理解不同方法的优缺点至关重要。要实现产业化应用,需选择最适合的技术路径。
ChipGPT 的技术虽较新颖,但传统程序合成思路在某些方面仍占优。所以,结合实际情况选择最佳技术,或将不同技术有机结合,这是产业化的关键。
总之,要实现芯片自动生成的广泛应用,必须在不断探索新方法的同时,理解每种方法的优势所在。将不同方法的优点有效融合,这可能是取得最大效益的关键。
在一定程度上,产业化依赖于技术创新,但更需要对不同技术有 objective 的判断和选择。这也是促进任何新技术广泛应用的基础。
 图片
图片
论文地址:https://arxiv.org/abs/2306.12456
结论出人意表?芯片自动生成之路恰恰漫长不过!
简而言之,大模型在芯片自动设计中的应用还面临以下困难:
1) 随机性和鲁棒性较差,会影响研究人员复现结果和现有算法对特性的约束。虽然 ChipGPT 采取措施加强稳定性,但大模型的鲁棒性还需提高。
2) 仍缺乏芯片全流程优化算法。现有方案只用于芯片逻辑设计的「小优化」。如何大模型做前后端协同优化,改变这种局限,值得探索。
3) 芯片数据库短缺。虽然闭源大模型较完善,但大量资源掌握在生产商手中。如果从开源库生成高质量数据集或把闭源代码库当作数据库,可以给开源模型训练带来优势,此可逆转这一劣势。
所以,要实现大模型在芯片自动设计中的深入应用,还需努力解决这些难题。提高大模型的稳定性和鲁棒性,开发芯片全流程优化算法,解决数据库短缺问题,这些都是实现更深入应用的关键所在。
对研究人员和企业来说,这些难题同时也代表新的研究方向和市场机会。能够有效解决这些问题,巨大潜力等着发掘。
现有设计方法只是起步,距离工程师自主设计和理解电路还较远。
团队介绍&致谢
ChipGPT 的一作为中科院计算所博士生常开颜,指导老师为中科院计算所王颖博士;上海科技大学硕士生任海蒙,中科院计算所博士生王梦迪参与工作;中科院计算所助理研究员梁胜文,中科院计算所韩银和、李华伟、李晓维研究员提供支持。
感谢中科院计算所王颖老师,首都师范大学李冰老师对本文的建议和指导,感谢中科院计算所硕士生林钢亮对本文的审阅。
© 版权声明
文章版权归作者所有,未经允许请勿转载。