
「社交达人」GPT-4!解读表情、揣测心理全都会
想象一下,您正在参加一个充满活力的鸡尾酒会,局间充满了热烈的谈话声和玻璃杯碰撞的叮当声。
此时,您作为一个悠闲的观察者,怡然自得地躲在角落里。然而,就算没有处在聚会的中心,您还是可以轻松地弄清楚不同人之间的社会关系,了解正在发生的事情,甚至通过阅读人们的言语和非言语线索来读懂明里暗里的社交信息。
如果一个LLM能够复现这种水平的社交能力呢?这不,Koko Mind就是这么个东西。
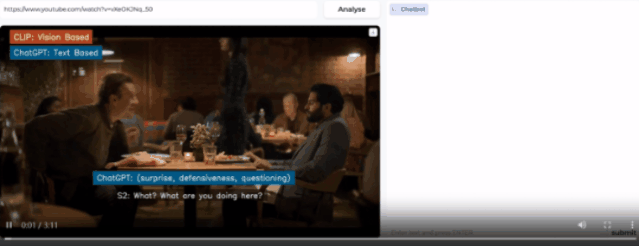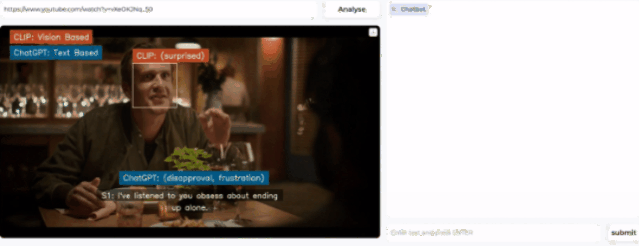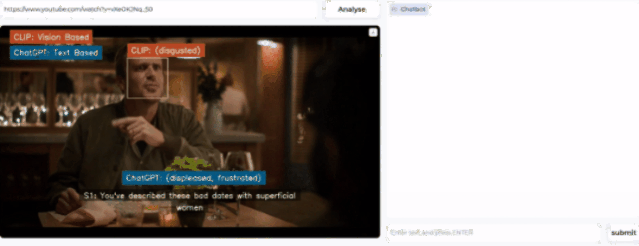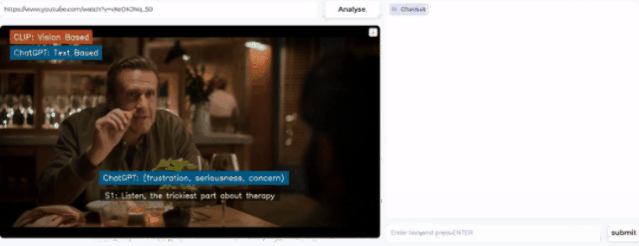
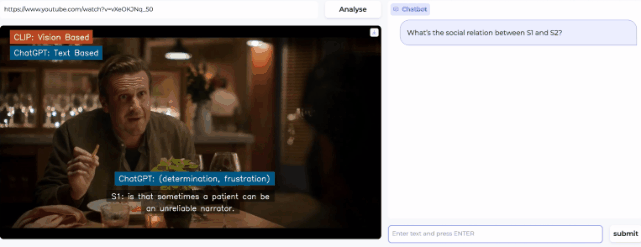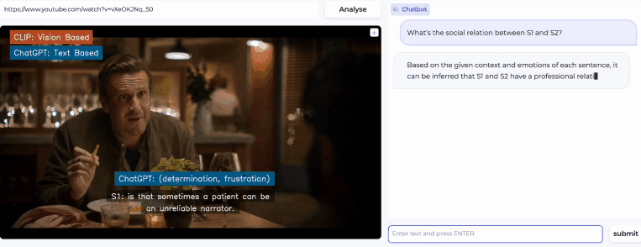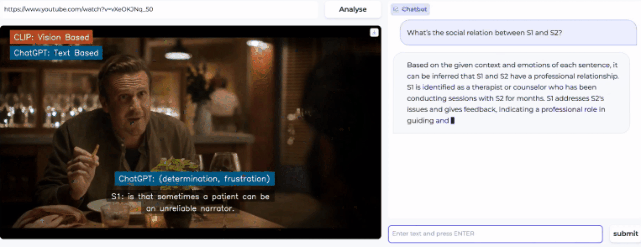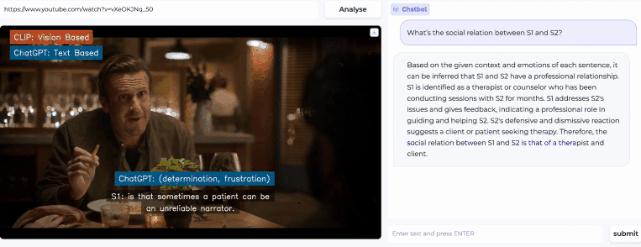
随便打开一个视频,该模型就开始分析人物表情,得出人物情绪的结论。
然后,在右侧的prompt栏还可以提出问题,让AI进一步分析视频中暗流涌动的社交谜题。
(说实话对有些人来说这都很难)
 图片
图片
Koko Mind包含了150个复杂的多方社交互动以及自由文本问题和答案。
为了确保数据的多样性和可扩展性,并避免数据污染,所有社交互动、问题和答案均由GPT-4生成,并随后由人类专家验证。
分析数据基于三个不同的来源:
- GPT-4-only:该子集仅由 GPT-4 通过提示创建。
- 基于电影:为了避免数据污染,这部分数据基于从2022年之后上映的电影中提取的各种场景。GPT-4负责塑造这些场景,在保留核心本质的同时添加了自己的元素。
- 基于 ToMi:该部分包含由模拟数据集ToMi支持的数据,其中涉及将物理对象移动到不同的地方,这是心理理论的经典测试。当然,这些社交互动还得被GPT-4修饰和扩展一下。
三种数据来源的占比如下:
 图片
图片
对于每次社交互动,研究人员都会提出各种问题,旨在探讨以下几个和社交理解息息相关的方面。
- 心理理论:评估对其他人心理状态和观点的理解的问题。
- 社会规范:旨在辨别情境中的社会价值观和规范的问题。
- 情绪识别:旨在识别和理解上下文中的情绪元素的问题。
- 社会关系:关注人际动态和关系。
- 反事实问题:旨在探索替代结果或可能性的假设查询。
- 社会建议:提出与特定情况相关的建议或行动建议的问题。
研究人员以text-davinci-003 作为参考,评估了AlpacaEval后的不同模型。
其中,研究人员从上下文中删除了括号中的非语言线索(例如,紧张地喝咖啡等)。
以下则是一些有趣的要点:
- 在两个模型中,与Claude相比,GPT-4在识别获胜模型方面表现出更大的确定性和信心。
- 当上下文没有非语言线索,且交互要么完全由GPT-4生成,要么基于电影时,Claude的表现优于 GPT-4。
- 而如果上下文包含了非语言线索,那GPT-4总是比Claude更好。
(一种可能的解释是,GPT-4是一种多模态模型可以更好地理解额外的非语言信息。)
在博客中,研究人员绘制了表格,可以清晰的看到各个模型的表现。
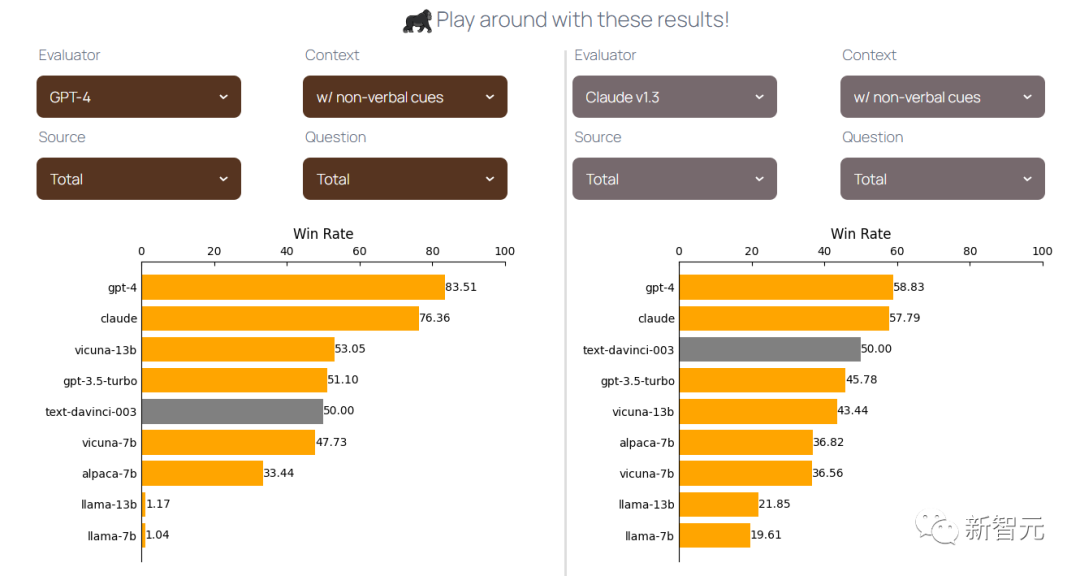 图片
图片
结果虽然在很多方面都令人兴奋,但也有一定的局限性。首先, Koko Mind的规模相对较小,这可能会限制研究人员结论的广泛适用性和全面性。
其次, Koko Mind中的所有交互都是由GPT-4生成的,需要人工验证,这使得数据集难以扩展。
另外,虽然Koko Mind在数据集中提供了经过人工验证的答案,研究人员在评估时没有使用这些答案作为参考,并且由于这些答案是由GPT-4生成的,因此它们可能会偏向GPT-4。
未来的研究可以集中在如何评估模型上具有经过人工验证的机器生成的参考答案。
当然,虽说存在这样或那样的限制,研究人员仍将Koko Mind视为未来与社会智能、多模态语言模型等相关的研究的跳板。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


